【深度】HBM行业深度解析!


热门主题产业链
5月29日,三星电子宣布,开始向主要全球客户交付业内首批12层48GB HBM4E样品。


作为HBM4的迭代升级产品,12层HBM4E采用第六代10纳米级DRAM工艺和三星晶圆代工的4nm逻辑基片,在性能、容量、能效与散热方面均有大幅提升,专为大模型、生成式AI及高性能计算场景打造。
今天解读一下 HBM 。
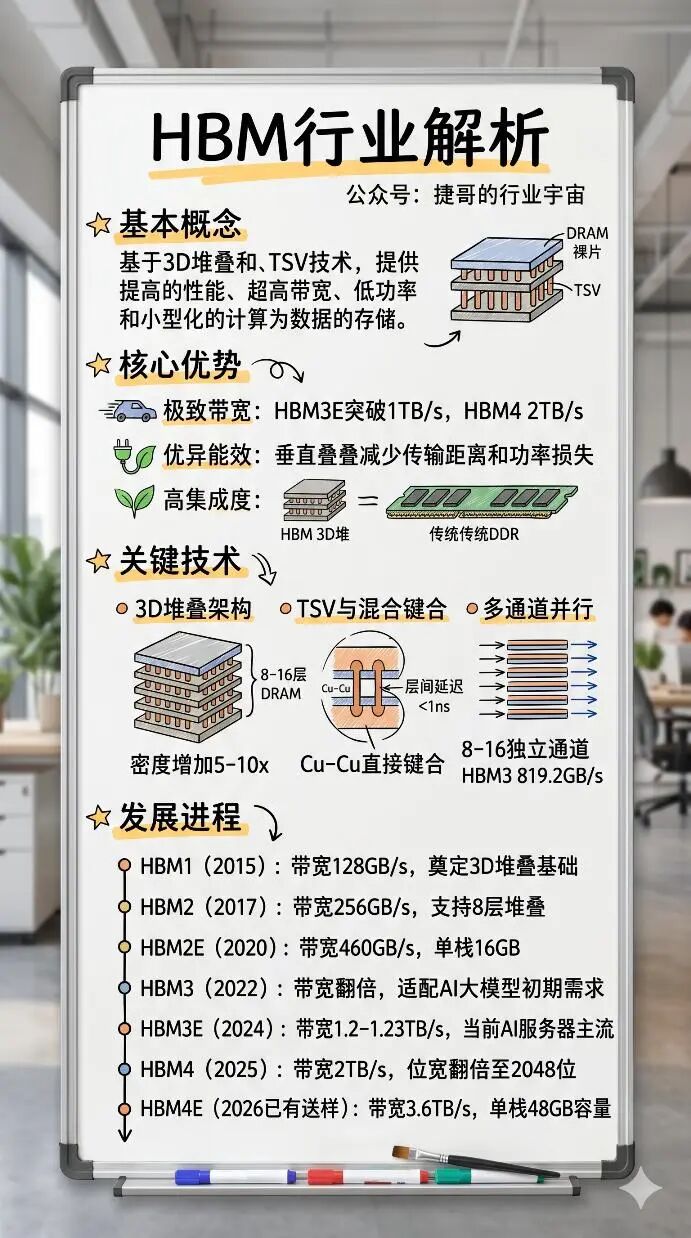
HBM基本介绍
HBM的概念
高带宽内存(High Bandwidth Memory, HBM)是一种基于3D堆叠工艺与硅通孔(TSV)技术的高性能DRAM存储解决方案。它的核心设计目标是突破传统内存架构的性能瓶颈,为数据密集型计算场景提供超高带宽、低功耗且小型化的存储支撑。

为什么HBM备受市场关注
上周(5月19日),英伟达CEO黄仁勋在Dell World大会期间表示,“AI企业部署最大的瓶颈不是算力,而是存储”。大力发展HBM,就是因为它解决了AI时代最致命的"内存墙"问题。
当前GPU算力每代提升3-4倍,但传统DDR内存带宽提升不到50%,两者差距持续拉大,导致GPU算力被严重浪费。
这一背景下,HBM就成为大模型训练和推理的"生命线"。训练时,参数和梯度在GPU间频繁传输,带宽不足会大幅延长训练周期;推理时,HBM容量直接决定单卡能承载的模型大小,带宽则决定并发请求数和响应延迟。
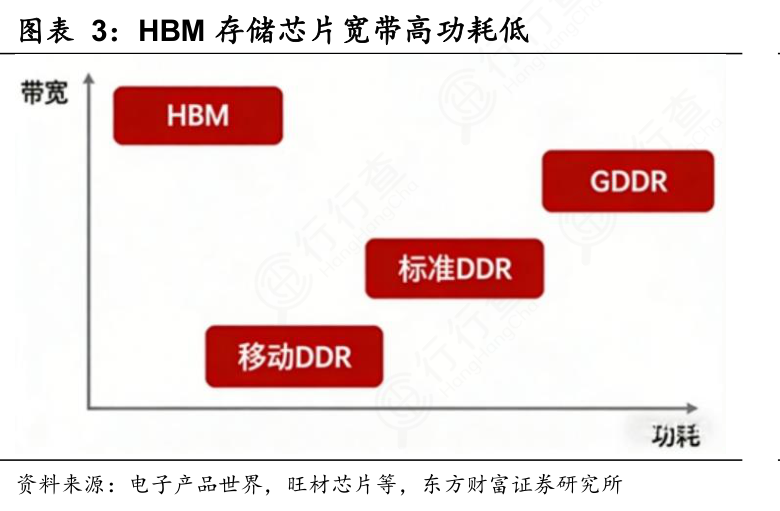
如今HBM已成为AI算力的核心瓶颈,其产能和良率直接决定全球AI服务器的出货量。掌握HBM技术,就能在AI产业链中占据关键话语权。
HBM的核心优势
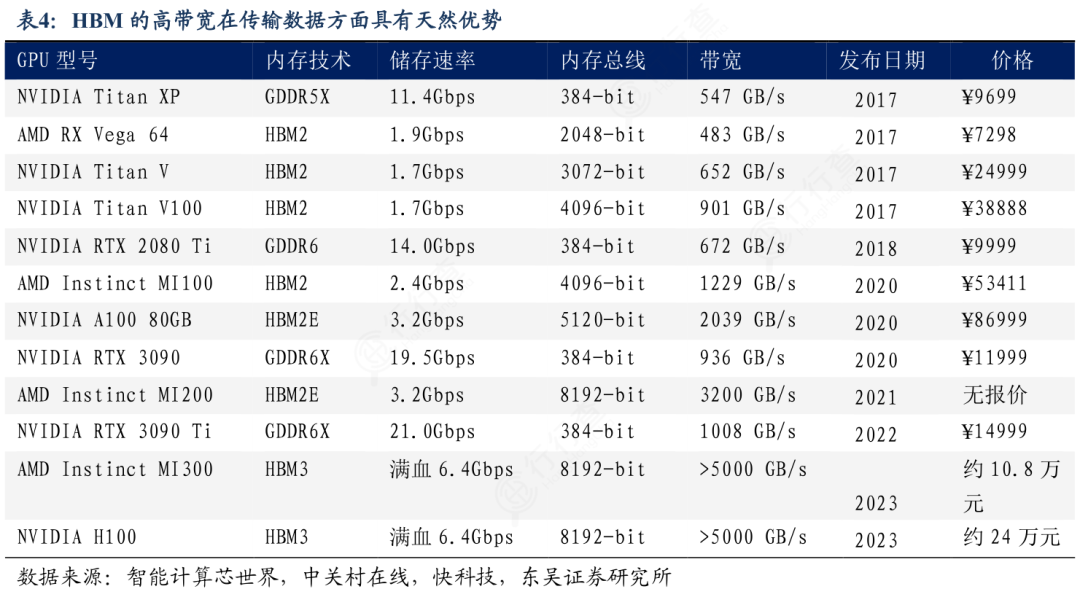
1)极致带宽性能
HBM通过超宽位宽设计与多通道并行传输,实现了带宽的指数级提升。当前量产的HBM3E带宽已突破1TB/s,下一代HBM4更是达到2TB/s,这种高带宽特性可满足海量数据的并行吞吐需求。
2)优异的能效比
HBM无需通过极端提升时钟频率来拓展带宽,且垂直堆叠缩短了数据传输距离,显著降低了信号衰减与功耗损耗,适配AIDC等对能耗敏感的场景。
3)高集成度与小型化
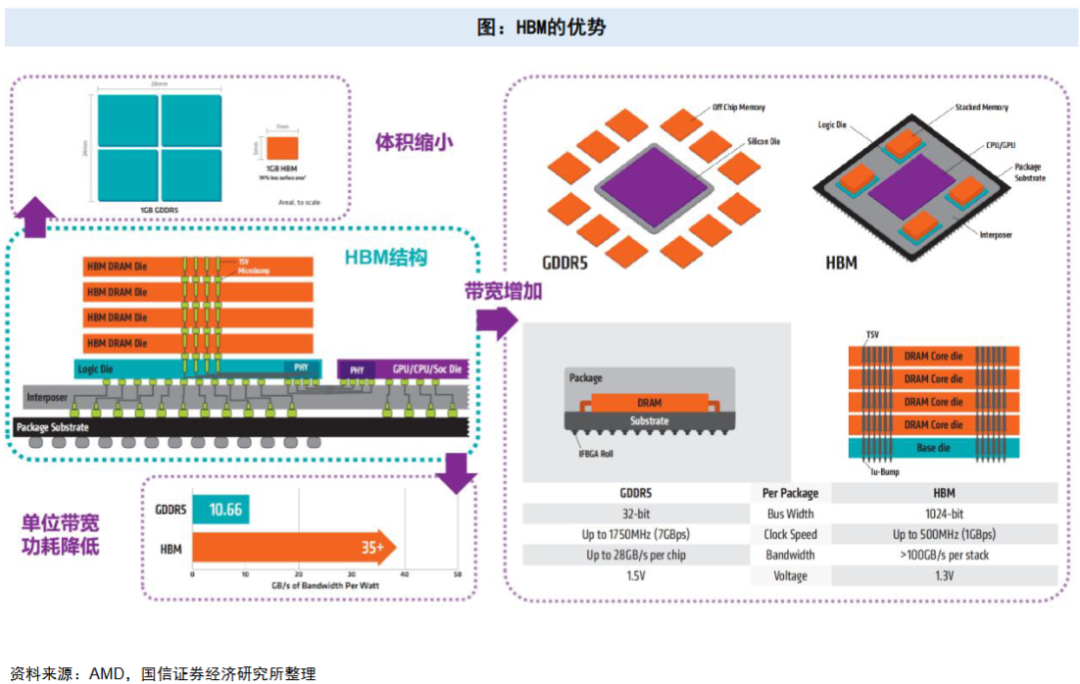
3D垂直堆叠结构大幅缩减了内存占用的PCB板空间,相同存储容量下,HBM的占地面积仅为传统DDR内存的1/10左右。这种小型化优势使处理器与内存的集成设计更紧凑,为高端芯片的轻薄化、高密度部署提供了可能。
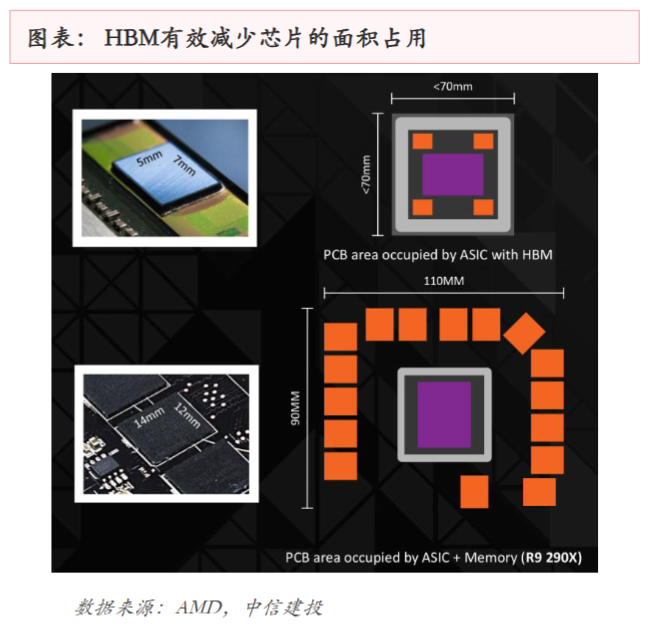
HBM的技术解析
HBM的基础架构
HBM的整体架构通过“主机芯片→逻辑芯片→硅中介层→DRAM堆叠体”的层级实现数据高速传输。
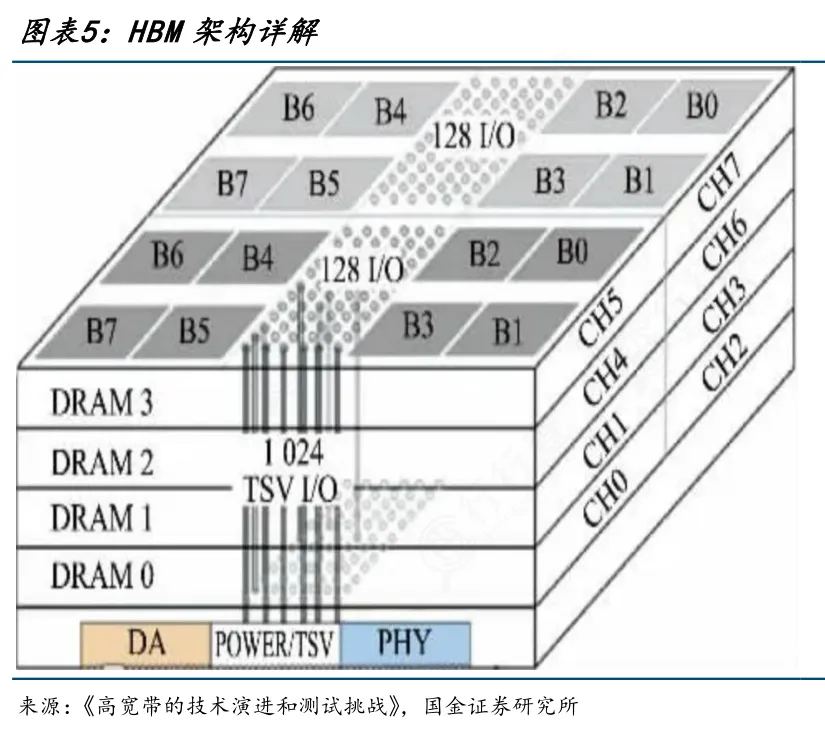
HBM的核心组件中,底部逻辑芯片作为控制中枢,负责通信与数据调度;硅中介层承担互联桥梁作用,解决触点密度匹配问题;3D DRAM堆叠体是数据存储核心,通过多层裸片垂直堆叠提升容量;TSV与微凸点构成高效互联通道,缩短传输路径、降低延迟。
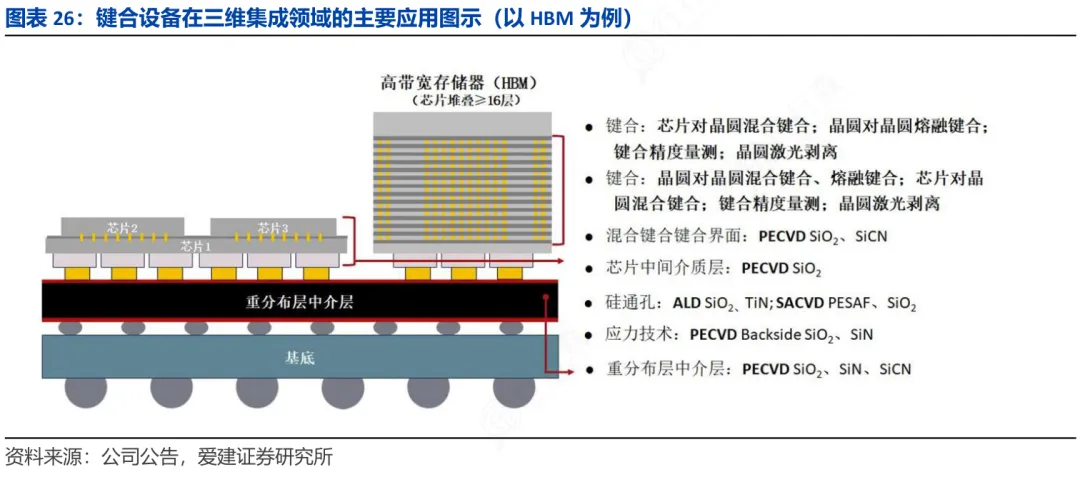
关键技术介绍
1)3D堆叠架构
HBM摒弃了传统DDR单芯片平面设计,采用8-16层DRAM裸片垂直堆叠方案,通过硅通孔(TSV)技术互联形成立体阵列。底层裸片经中介层与CPU/GPU对接,上层专注存储,存储密度提升5-10倍,同时缩短传输路径,奠定高带宽并行访问基础。
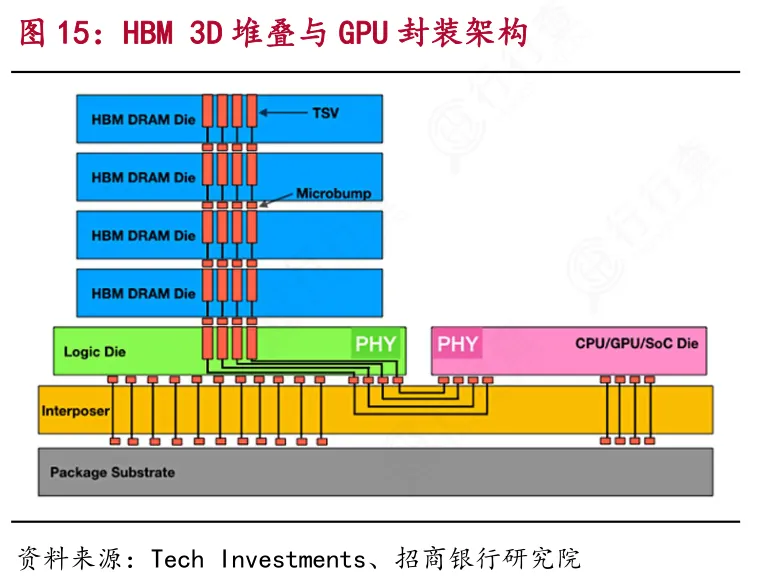
2)硅通孔(TSV)与混合键合
早期HBM采用的是“TSV+微凸点”实现信号与电力传输;新一代HBM3e/HBM4引入混合键合(铜-铜直接键合+硅通孔TSV),传输速率提升数倍,接触电阻与信号衰减降低,层间传输延迟可控制在1ns以内。
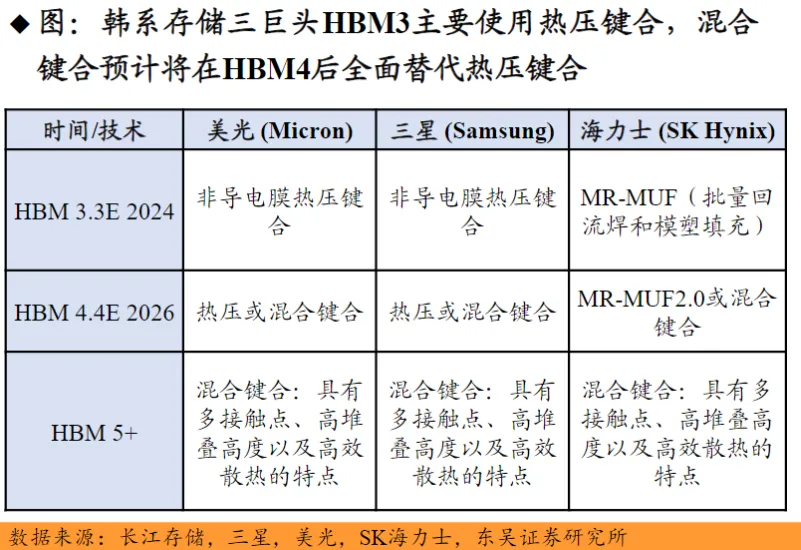
3)多通道并行架构
HBM采用8-16个独立通道并行设计,各通道配备专属总线与控制逻辑。以HBM3为例,单通道位宽128位,速率6.4Gbps,单颗芯片总带宽达819.2GB/s,可让GPU、AI加速器等计算芯片同时访问多区域,避免单通道瓶颈,提升吞吐效率。
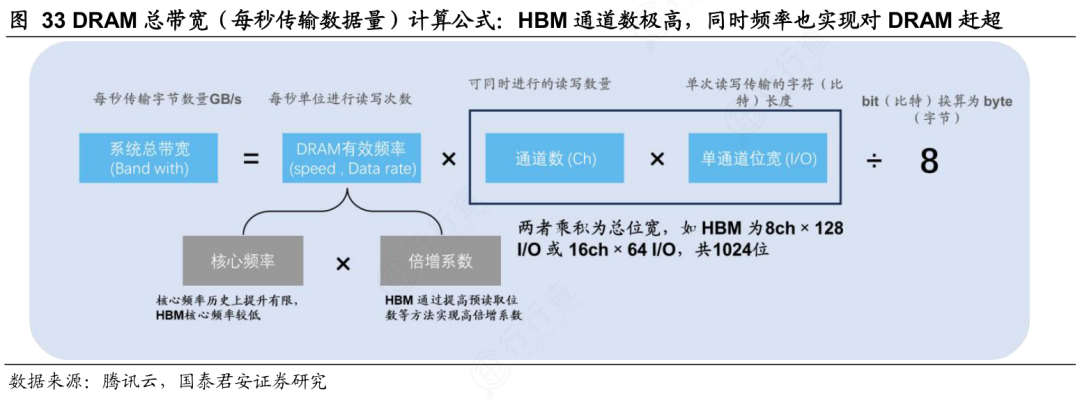
HBM的代际发展进程
HBM1(2015年量产)
HBM1是初代HBM技术,堆叠4个4Gb核心晶片,带宽约128GB/s,仅支持传统模式操作,主要用于早期高端显卡,奠定了3D堆叠与TSV互联的基础架构。

HBM2(2017年量产)
HBM2带宽提升至256GB/s以上,支持2、4或8层核心晶片堆叠,引入伪通道、隐式预充电操作和ECC存储等新功能。优化了命令带宽并降低延迟,有效提升了传输效率,成为高端GPU的主流配置。

HBM2E(2020年量产)
HBM2E垂直堆叠8个16Gb芯片,容量为16GB,是HBM2的两倍。处理速度达3.6Gbps,每秒可处理460GB的数据,是当时业界最快的存储器解决方案。

HBM3(2022年量产)
HBM3核心晶片密度从8Gb翻倍至16Gb,支持4-16层堆叠,峰值带宽较HBM2E翻倍,进一步提升了容量与能效,适配AI大模型训练的初期需求。

HBM3E(2024年量产)
HBM3E单栈峰值带宽突破1TB/s,主流量产规格达1.2-1.23TB/s,支持8-12层堆叠(对应24GB/36GB单栈容量),优化了信号完整性设计,并通过先进封装工艺提升散热效率,已成为当前高端AI服务器的主流配置。

HBM4(2025年量产)
HBM4的位宽将翻倍至2048位,带宽突破2TB/s,支持1.1V/0.9V低电压选项,每比特传输能效大幅提升,可进一步满足万亿参数模型的存储需求。

今年,英伟达正式推出rubin系列芯片,rubin成为首款集成HBM4内存芯片的GPU,其带宽为22TB/s,而Blackwell NVL72 HBM3E的仅为16 TB/s;英伟达同时推出了Rubin NVL72架构系统,其HBM4容量达到 20.7TB,而Blackwell NVL72 HBM3E 为13.4TB/s
HBM4E(2026年已有样品交付)
HBM4E是第四代高带宽内存技术的增强版本,主要应用于人工智能、高性能计算及数据中心领域。该技术采用32Gb DRAM裸片,通过12层垂直堆叠实现单堆栈48GB容量,数据传输率达14Gbps,配合2048位内存接口可实现3.6TB/s带宽,较前代HBM4提升20%。

HBM市场规模与格局
根据IDC披露数据,2024年全球HBM市场规模为179.62亿美元,受益于全球AI芯片对HBM的需求,预计2025、2026年需求加速增长,2024-2026年的年均复合增速约为60%。远期来看,IDC预计2029年全球HBM市场规模将达到575.4亿美元。
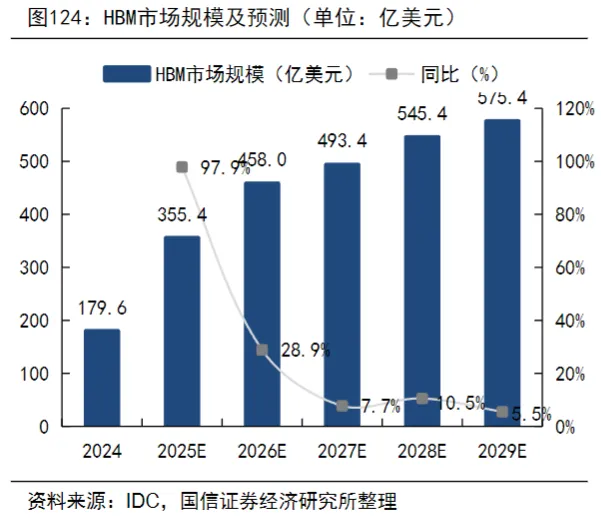
(数据时间:2025-12)
从全球出货量来看,2024年全球HBM出货量为14.97亿GB,预计2029年将达到64.77亿GB,对应2024-2029年的年均复合增速约为30%-40%。
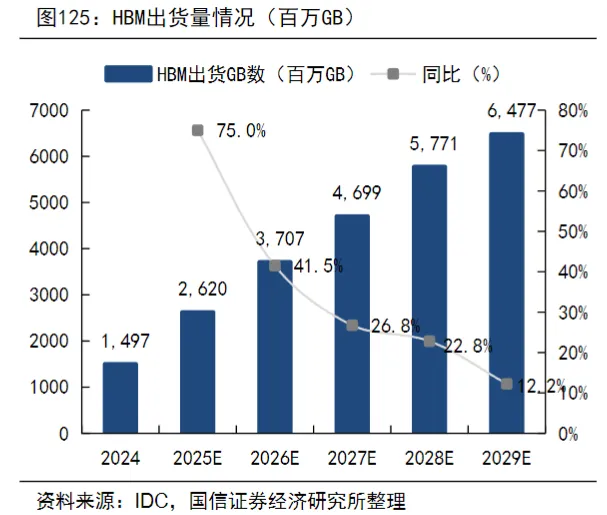
(数据时间:2025-12)
根据博研咨询的数据,随着中国东数西算工程推进和各地智算中心建设提速,预计2025年中国HBM市场需求将继续保持高速增长,市场规模有望达到49.8亿美元,同比增长45.6%。
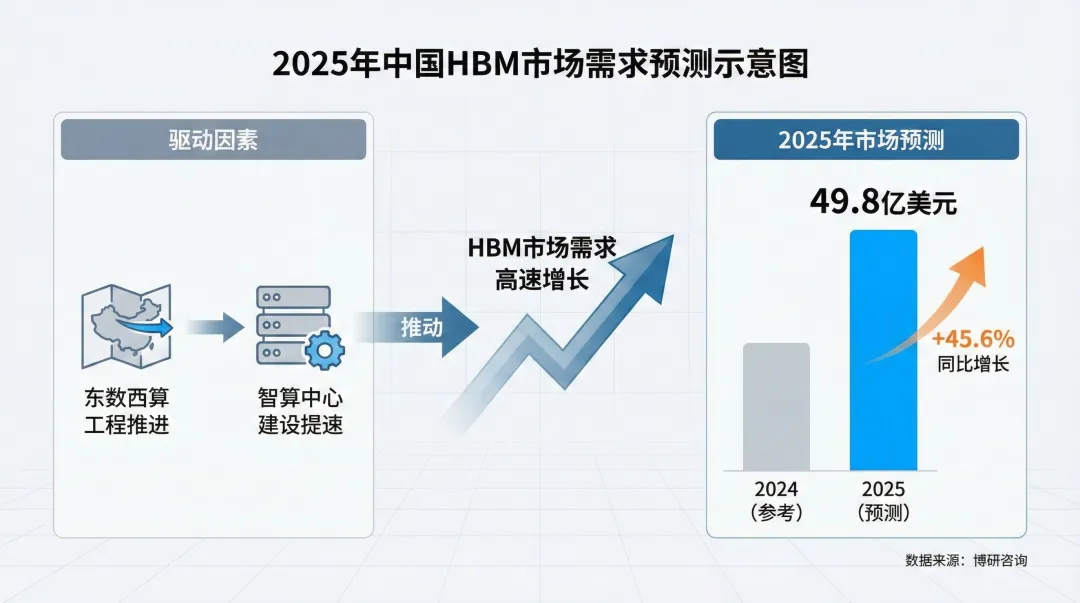
(图片由AI制作,数据时间:2025-12)
从行业格局上看,当前全球HBM市场呈现高度垄断态势,由SK海力士、三星电子和美光科技三家巨头瓜分,合计市占率接近100%。由于技术门槛极高、先进封装(如CoWoS、MR-MUF)能力稀缺,新玩家几乎无法直接切入。

国内存储龙头厂商如长鑫存储、长江存储等企业的HBM产品正加紧进行关键客户的合规验证与产能爬坡,2026年正式迎来本土HBM的量产大考。
预计未来1-2年内,国产HBM将在关键技术攻关与本土算力客户验证上取得实质性突破,逐步实现底层算力供应链的自主可控。
先进封装行业代表性企业
海外代表性企业:
SK海力士(韩国,全球HBM市场份额第一)
三星电子(韩国,HBM技术与产能双领先)
美光科技(美国,HBM3E已实现规模量产)
安靠科技(美国,全球第二HBM封测厂商)
Rambus(美国,HBM接口芯片技术领先)
住友化学(日本,HBM专用GMC材料龙头)
东京电子(日本,HBM制造核心设备供应商)
中国代表性企业:
长鑫存储(合肥,国内DRAM与HBM龙头)
长江存储(武汉,3DNAND龙头布局HBM)
武汉新芯(武汉,HBM先进封装代工龙头)
日月光(中国台湾,全球HBM封测市占第一)
太极实业(无锡,SK海力士HBM封测基地)
长电科技(江阴,全球第三HBM封测厂商)
深科技(深圳,国内唯一英伟达HBM3封测)
通富微电(南通,长鑫HBM封测合作伙伴)
兴森科技(广州,HBM用ABF载板量产)
华海诚科(连云港,HBM专用GMC国产唯一)
雅克科技(无锡,全球HBM前驱体三大龙头)
赛腾股份(苏州,HBM全制程检测设备量产)
来源:捷哥的行业宇宙
展开阅读全文