炸穿天际!存储超级周期狂飙!存储创新相关标的梳理


热门主题产业链
近期,海外存储巨头市值接连创下新高。周二,闪迪的股价大涨12%,目前市值约为2075亿美元。周三,三星电子大涨11%,市值突破万亿美元,成台积电之后第二家达到该规模的亚洲公司。SK海力士周三当日也大涨约10%,目前市值约7750亿美元。
今年一季度,AI多模态迭代引发了庞大的数据吞吐需求,供应链端出现明显的供不应求,DRAM与NAND现货价格大幅跳涨。存储芯片摆脱周期性波动的预期,可能重塑行业估值逻辑,吸引长期资本流入。
一、存储供需缺口长期存在
2023-2024年海力士等存储厂一直在进行减产动作,传统存储芯片产量将持续下降,整体产能提升相对受限。据2023年四季度海力士财报电话会,始于2022年末的减产,主要集中于低利润、高库存的传统存储芯片,预计减产将会持续,直到库存降至足够低的水平,且产品价格回升至盈利水准。
目前全球主要DRAM制造商三星、SK 海力士及美光都积极增加产能,但绝大部分新建产能最快要到2027年才能上线,有些产能甚至需要等到2028年才会开出。2026年除了SK海力士2月于韩国清州一座新厂投入量产外,三家制造商几乎没有更多产线贡献产能。


与此同时,三星等主要制造商已相继停产DDR3、DDR4及LPDDR4等传统规格内存,将资源集中投向利润更高的HBM和SOCAMM2等产品线。美光旗下面向消费端的Crucial品牌也已宣告退出,进一步收窄了PC用户和整机厂商的供货渠道。
研究机构Counterpoint数据显示,2026至2027年间DRAM年产能需以12%的速度增长才能缓解短缺,而当前实际增速仅约7.5%,缺口仍然较大。这一缺口叠加新厂建设的固有周期,使得任何实质性的供需再平衡都难以在2027年之前出现。
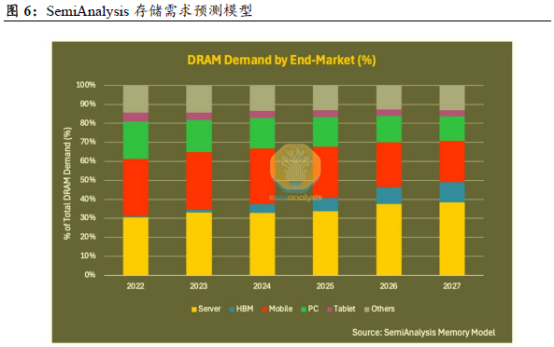
二、下一代存储创新
存储厂商的创新核心围绕解决AI推理时代的存储瓶颈,特别是应对KV缓存爆炸式增长带来的挑战,创新主要体现在HBF、DPU(如英伟达BlueField)、LPU、智能存储软件等,旨在将存储从被动设备转变为主动参与计算的关键组件。
02-1 HBF
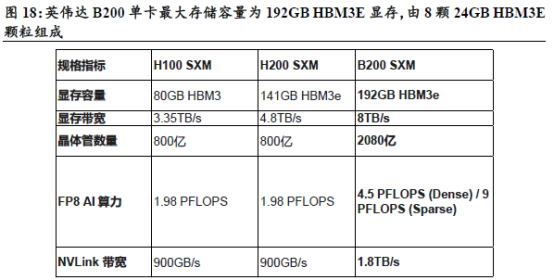
AI工作负载的瓶颈不再是计算性能,在应对超大规模模型时,HBM容量局限性已成为关键因素。以英伟达B200为例,其单卡最大存储容量为192GB。相比之下,Llama3.1 405B模型在FP8模式下对存储的需求约为405GB。为了运行405GB模型,必须使用多GPU并行,如通过超节点NVLink连接的8卡系统,当模型被切分到多个GPU时,卡与卡之间的数据通信会产生延迟。若不考虑超节点方式,一旦数据溢出HBM范围,访问速度会断崖式下跌,导致昂贵的GPU 算力被大量浪费在等待数据加载的过程中。
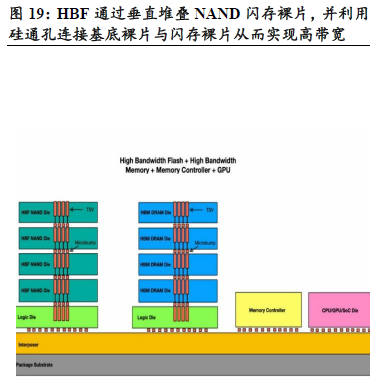
高带宽闪存(HBF)通过垂直堆叠NAND闪存裸片,并利用硅通孔(TSV)连接基底裸片与闪存裸片,从而实现高带宽。目前,多家存储与闪存厂商正在研发HBF,目标是达到与HBM相近的带宽,同时提供远大于HBM的容量。
HBF具备如下特点:
1)高带宽:提供可比拟HBM 的带宽(如1.6TB/s)。
2)大容量:单个堆栈可达512GB,容量是HBM 的8-16 倍。
3)低成本:作为NAND的衍生,成本低于DRAM为基础的HBM。
02-2 CMX
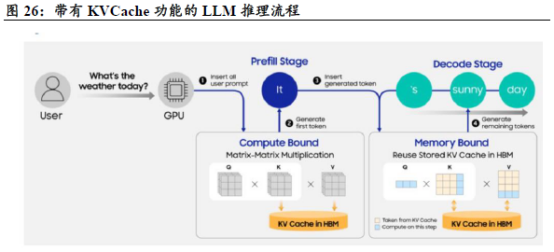
随着需要生成的标记数量越来越多、生成速度也越来越快,以及对话上下文的增加,GPU内存的限制就变成了一个关键的瓶颈。因此,利用KV Cache来缓解这一问题,就成了扩展推理处理能力的关键手段。
推理过程大致可以分为两个阶段:
1)预填充阶段:在预填充阶段,系统会对提示词进行处理,从而生成初始的键值对集合。这些键值对会被存储在HBM中,作为键值缓存使用。
2)解码阶段:模型会重新利用HBM 中存储的键值对缓存,以及最近生成的标记,来生成下一个标记。此时,只需计算与新标记对应的键值对即可。如果解码阶段利用了存储、增加存储容量,它能够存储之前计算过的数据,从而缩短生成下一个标记所需的时间。
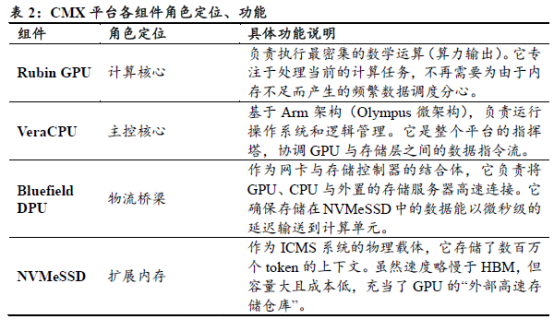
2026年英伟达推出的“推理上下文内存存储”(ICMS/CMX)平台,是一个基于Bluefield DPU和标准SSD的已发布系统方案。该平台不仅包含Rubin GPU和基于ARM架构的Vera CPU,其核心创新在于引入了ICMS推理上下文内存存储“G3.5”层这一全新存储层级。G3.5层NVMe介于G3层DRAM和G4层共享存储之间,通过Bluefield网卡连接到计算服务器的存储服务器。
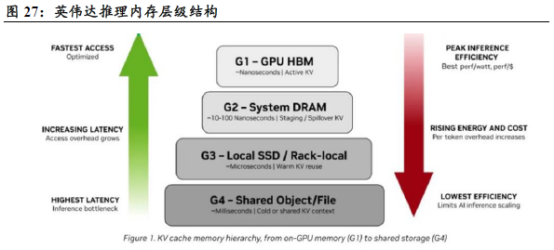
CMX平台中,由于GPU/HBM的缓存容量有限,而DPU则能让GPU/HBM以较低的延迟访问远程存储设备,从而提升计算速度,减轻GPU/HBM的负担。它利用NVIDIA BlueField-4数据处理器,在pod级别构建专用的上下文内存层,弥合高速GPU内存和可扩展共享存储之间的差距。这加速了KV缓存的数据访问,并实现了pod内各节点间的高速数据共享,从而提升性能并优化功耗,以满足日益增长的大规模上下文推理需求。
02-3 LPU
过去人工智能推理架构要么以牺牲吞吐量为代价来提供交互性和智能性,要么以牺牲交互性为代价来提供吞吐量和智能性,吞吐量、交互性和智能性三者不可兼得。
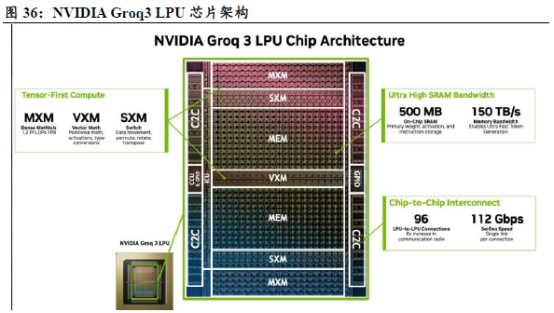
NVIDIA Groq3 LPX是NVIDIA Vera Rubin的推理加速器,旨在满足智能体系统对低延迟和大上下文的需求。Vera Rubin和LPX通过协同设计的架构,将NVIDIA Rubin GPU 和LPU的卓越性能完美结合。
NVIDIA Vera Rubin with LPX结合了Rubin GPU的HBM和LPU的SRAM,为万亿参数模型和百万级词元上下文提供了全新的推理性能。与Vera Rubin NVL72配合使用时,Rubin GPU和LPU通过联合计算每个输出词元的AI模型每一层,显著提升解码性能。
三、相关标的
江波龙:国内存储模组龙头,专注于企业级SSD领域;与闪迪有长期合作基础,已布局HBF相关技术研发。
佰维存储:掌握16层堆叠及超薄带封装工艺,松山湖晶圆级先进封测项目聚焦HBM与Chiplet异构集成,可满足HBF高端存储需求。
华海诚科:国内唯一量产颗粒状环氧塑封料(GMC)的企业,该材料是HBM/HBF封装的关键,已通过SK海力士认证。
飞凯材料:在半导体先进封装领域有全链条材料储备,开发的临时键合材料、液体及颗粒封装材料可适配HBF工艺。
兆易创新:国内存储芯片龙头,提供LPU所需的多种容量和接口类型的SRAM芯片,覆盖NOR Flash、DRAM全系列。
北京君正:SRAM存储芯片领先企业,为LPU提供高带宽、低延迟的SRAM存储支持,低功耗技术契合LPU能效需求。
(特别说明:文章中的数据和资料来自于公司财报、券商研报、行业报告、企业官网、百度百科等公开资料,本报告力求内容、观点客观公正,但不保证其准确性、完整性、及时性等。文章中的信息或观点不构成任何投资建议,投资人须对任何自主决定的投资行为负责,本人不对因使用本文内容所引发的直接或间接损失负任何责任。)
来源:策金说
展开阅读全文