国产超节点:算力核心赛道的逻辑拆解


热门主题产业链
模型迭代持续提速,算力需求迎来爆发式增长,当前AI大模型周调用量已达27万亿Token,传统服务器堆叠模式受限于松耦合架构的先天不足,已难以承载这一算力需求井喷,分析师普遍看好,国产超节点发展势在必行,有望成为承载万亿级算力需求的关键基座。
本文结合行业核心数据与最新动态,拆解分析国产超节点的核心逻辑,仅供行业研究参考。
一、什么是超节点?
首先明确核心概念:超节点是指通过高速互联总线将数千张AI芯片整合为逻辑统一的计算集群,区别于松耦合的服务器堆叠,作为打破“堆服务器扩算力”旧模式的核心解决方案,已然成为国产算力突围的关键抓手。
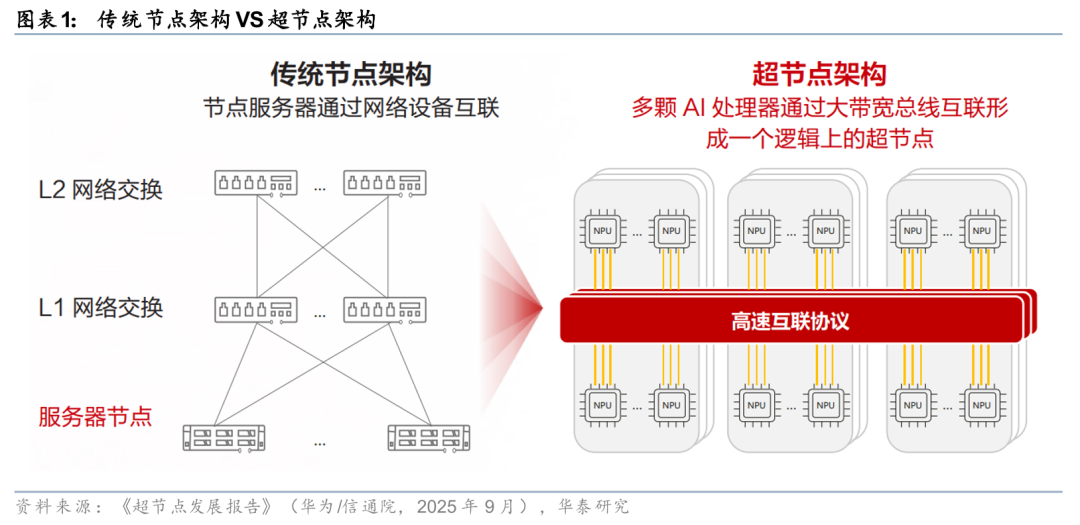


技术演进目标:
彻底打破“堆服务器扩算力”的低效旧模式,实现AI算力效能的革命性提升。
二、需求侧:
AI训推共振,算力缺口倒逼超节点落地
这一需求井喷的态势,正是超节点需求爆发的核心驱动力。
据OpenRouter数据,3月30日至4月5日这一周,全球AI大模型总调用量达27万亿Token,环比增长18.9%;

其中国内周调用量达12.96万亿Token,环比增幅高达31.48%,阿里通义千问Qwen3.6 Plus(free)以4.6万亿Token的周调用量,直接登顶全球榜首,进一步印证了万亿级算力需求的现实体量,也凸显了传统服务器堆叠模式的局限性。

更值得关注的是,算力需求结构的差异愈发明显,训练与推理对超节点的核心要求截然不同:
训练场景侧重大规模集群的协同算力,对互联带宽、时延容错性要求极高;
推理场景则更看重单机算力密度与能效比,需适配高频次、低延迟的调用需求,而AI推理需求的崛起正成为新的增长亮点。
英伟达CEO黄仁勋曾明确表示,AI推理规模很快将达到训练负载的十亿倍,IDC也预测,到2028年推理工作负载占比将攀升至73%。
近期Kimi、MiniMax等厂商的API调用频繁出现过载情况,再叠加全球算力涨价潮,国内“算力荒”问题进一步凸显,而超节点的高密度集成优势,正是破解这一缺口的最优路径。
三、供给侧:
技术迭代+政策支撑,超节点进入放量期
从供给端来看,超节点正朝着“密度集成、高速互联、全局协同”的方向加速演进,再加上政策与技术的双重支撑,整个行业已步入快速发展的快车道。
算力规模方面,IDC预测到2028年将进一步增长至2781.9 EFLOPS。
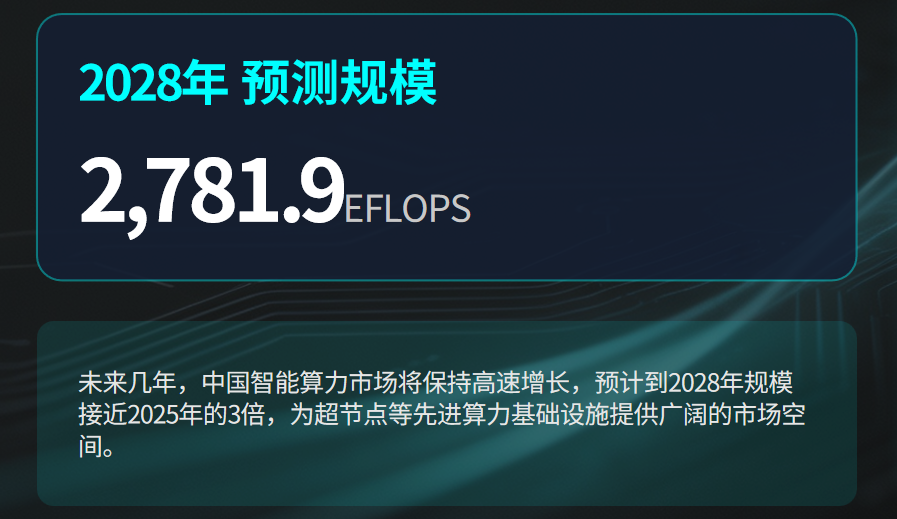
据华泰证券测算,
2028年国产超节点市场空间有望达到3414亿元,2026至2028年复合增长率高达194%。
测算核心依据为:当前每EFLOPS超节点造价约1.2-1.5亿元,叠加2028年国内智能算力渗透率提升至85%、超节点替代传统服务器集群比例达60%的假设,具备较强可验证性。
技术突破上,HW灵衢协议取得重大进展,其核心价值的在于破解传统PCIe、RoCE互联的核心瓶颈——PCIe带宽有限且时延较高,RoCE协议易受网络拥堵影响导致算力损耗,而灵衢协议实现带宽与时延的双重优化,其Atlas 950 SuperPoD超节点带宽达到16.3PB/s,时延降至3微秒,8192卡规模集群的性能表现,大幅领先于业界同类产品。
政策层面,“算电协同”已被写入“十五五”规划,明确要求枢纽节点新建算力设施的绿电应用占比不低于80%,这也推动超节点向绿色化、集约化方向升级,目前贵州贵安新区等算力枢纽已率先实现超节点规模化落地。
在这些因素的共同推动下,超节点正逐步替代传统服务器集群,成为智算中心的核心部署形态。

四、厂商格局
分层布局,国产玩家差异化突围!
国内互联网企业与整机厂商正加速布局超节点,目前已形成“超大规模、大规模、中型”三层产品矩阵,差异化适配不同应用场景,国产替代的趋势愈发明确。
1.超大规模超节点方面,目前全球主流方案包括HW Atlas 950 SuperPoD(8192卡)、谷歌TPU v7 Pod(9216卡)、英伟达DGX SuperPOD(2048卡),三类方案差异显著。
谷歌TPU Pod侧重自研芯片与软件生态闭环,适配自身AI训练需求,对外兼容性较弱;
英伟达DGX SuperPOD依托CUDA生态优势,软硬件协同性强,但核心芯片依赖自身供应,且受海外出口管制影响较大;

HW Atlas 950 SuperPoD则凭借自主研发的灵衢2.0协议,在算力、带宽等核心指标上实现对海外产品的超越,同时贴合国内“算电协同”政策,绿电适配性更强,这种自主协议+政策适配的组合,构成国产超节点的非对称优势,该产品计划于2026年四季度正式发布。

2.大规模超节点领域,厂商竞争最为激烈,阿里云磐久、中科曙光ScaleX640、字节大禹等方案均在其中布局,这类方案很好地平衡了单柜集成度与扩展灵活性,能够适配互联网大厂的大规模算力需求,也是当前市场放量的核心梯队。

3.中型超节点,则以超聚变FusionPod、新华三UniPodS8000、浪潮元脑SD200(均为64卡)为代表,主要聚焦企业级私有化部署与边缘智能场景,通过架构创新提升算力密度与能效比,精准满足细分市场的需求。
除此之外,寒武纪、摩尔线程等国产芯片厂商也在同步发力,通过训推一体架构优化、开源工具链完善,推动超节点软硬件协同升级,逐步打破海外生态的垄断格局。
五、产业链价值测算
超节点将成为算力的主流形态,意味着在未来,算力需求方的采购,将以超节点为单位,而不是GPU卡。
从价值量来看,超节点与光刻机在同一量级。

从产业链环节价值看,以HW Atlas 950作为测算标准,具体如下:
1.单套超节点造价估算
HW官方目前仅公开了Atlas 950/960超节点的技术参数与上市时间表,未披露具体售价。下文造价数据系产业链调研口径推演估算:
Atlas 950 SuperPoD(8192卡) :按零部件拆解和专业测算框架拟合,单套超节点投资约1.2亿美元(约合人民币8.6亿元) ,含芯片、互联组件、散热、整机组装等核心环节的成本摊分;
Atlas 960 SuperPoD(15488卡) :更高规格配置下,单套投资约3.1亿美元。
上述造价数值属于公开市场推演估算,实际造价可能因具体配置差异、采购规模、代工工艺良率等因素产生浮动(估计合理误差范围约±20% ),仅供参考。
2. 产业链价值量测算
以下产业链价值量占比,综合华泰证券、华西证券、长城证券等机构的公开研报及产业调研资料拟合得出,测算口径如下:
基准型号:Atlas 950 SuperPoD,单套造价估算值8.6亿元人民币;
年出货量假设:对应2026—2027年国产超节点放量过程的乐观情景假设,为数值计算提供可比标准(实际出货量范围可能在300~1000套/年之间,各环节金额按比例线性调整);
测算范围:覆盖从先进制程晶圆代工、封装、HBM存储、Scale-up交换芯片、高速铜缆模组、光模块、电源、液冷、PCB、DrMOS、散热盖在内的全产业链环节,不含数据中心土建及运营成本;
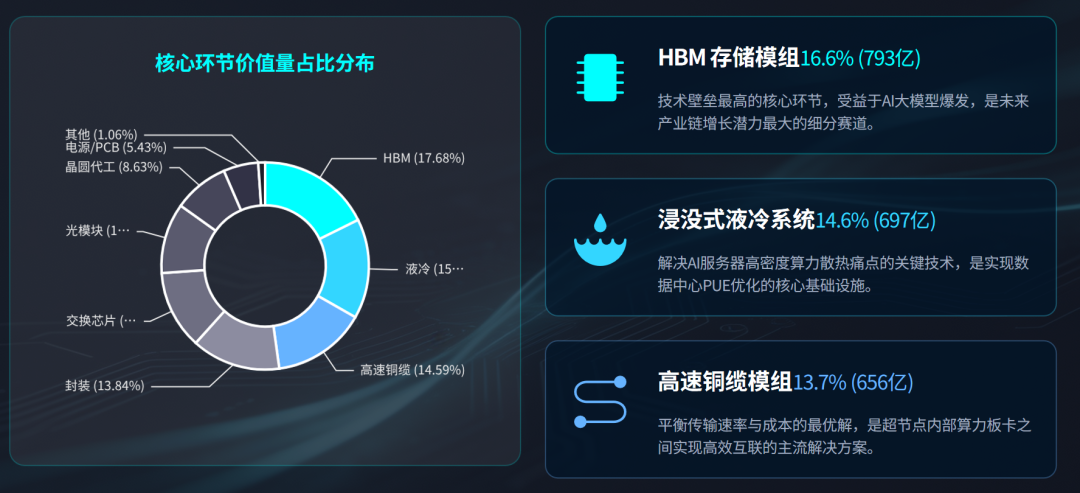
数据来源:综合多家券商研报中的子环节价值量推算拟合,各环节具体占比在不同机构之间存在口径差异。上文占比及绝对金额为产业模型推算值,实际数值可能存在±20%~30%的误差,不可直接替代官方或审计数据,仅供研究讨论参考。
基于上述前提与方法,年出货1000套时各环节价值分布如下:
先进制程晶圆代工约388亿元、封装约624亿元、HBM约793亿元,Scale-up交换芯片约549亿元,高速铜缆模组约656亿元,光模块约492亿元,电源约246亿元,液冷约697亿元,PCB约246亿元,DrMOS约41亿元,散热盖约42亿元。
其中,HBM(16.6%) 技术壁垒最高,增长潜力最大液冷(14.6%) AI算力密度提升的关键高速铜缆(13.7%)机内互联的核心解决方案。
3. 造价对标(仅供参考)
将超节点造价量与ASML光刻机进行类比,主要为了说明超节点在战略价值与造价量级上的可比性。ASML TWINSCAN NXE:3600D售价约2亿美元,High-NA EUV系列约3.5~4亿欧元(约27~32亿元),其价格主要体现技术与专利垄断壁垒;而超节点造价则更集中于硬件规模、互联架构与整机组装的系统集成成本。
六、六大核心环节
当前国内AI大模型已进入加速发展阶段,国产超节点的量产与渗透率提升具备较强确定性,算力板块的高景气度将持续延续。

平台玩家梯队
第一梯队:全球绝对领先(技术 + 规模双优)
第二梯队:技术领先且具备大规模部署能力
第三梯队:特色技术突出 / 部分领域创新
产业链细分领域:
关键部件:HBM 存储
温控散热:液冷技术
互联:高速铜缆模组
制造:先进封装技术
网络:Scale-up 交换机
光通信:高速光模块
制造:晶圆代工
基板:PCB/FCCL
供配电:电源 PSU
核心器件:功率半导体

重点梳理以下六大核心环节:
1.国产芯片:寒武纪、海光信息、摩尔线程等标的,将直接受益于国产替代推进与训推需求爆发,其中寒武纪思元590已实现千卡级集群商用部署,落地进度领先;
2.CPU:澜起科技、龙芯中科等企业,为超节点计算性能升级提供核心支撑;
3.ODM厂:浪潮信息、中科曙光、紫光股份等,直接受益于超节点整机放量,近期东山精密等企业就因算力相关业务,带动业绩实现显著增长;
4.IDC:润泽科技、光环新网等企业,依托算力枢纽布局,将持续受益于超节点的规模化部署;
5.零部件:华丰科技、中航光电等,为超节点的高速互联需求提供核心配套;
6.液冷:英维克、川环科技等标的,适配超节点高密度集成下的散热需求,叠加绿色算力政策导向,行业需求将持续提升。
七、风险
短期风险:算力涨价导致下游应用厂商成本压力攀升,进而拖累超节点的部署节奏;国产大模型性能成长、AI产品落地进度不及预期,进而导致算力需求不及市场预期;
结构性风险:
1. 国产超节点技术突破进度缓慢,或海外巨头技术封锁加剧,影响国产化推进进程;
2. 国产算力生态建设进度不及预期,难以突破海外CUDA生态的垄断壁垒,导致超节点软硬件协同效率受限。
整体来看,国产超节点是AI算力需求爆发与国产替代双重逻辑共振下的核心赛道,技术迭代、政策支撑与厂商发力形成合力,正推动行业进入快速发展期。对行业研究者而言,需重点跟踪技术路径的演进方向;对投资者来说,可聚焦核心环节标的,兼顾成长性与确定性,同时警惕行业潜在风险。
----------------
附表:
表1:国产超节点产业链与核心公司
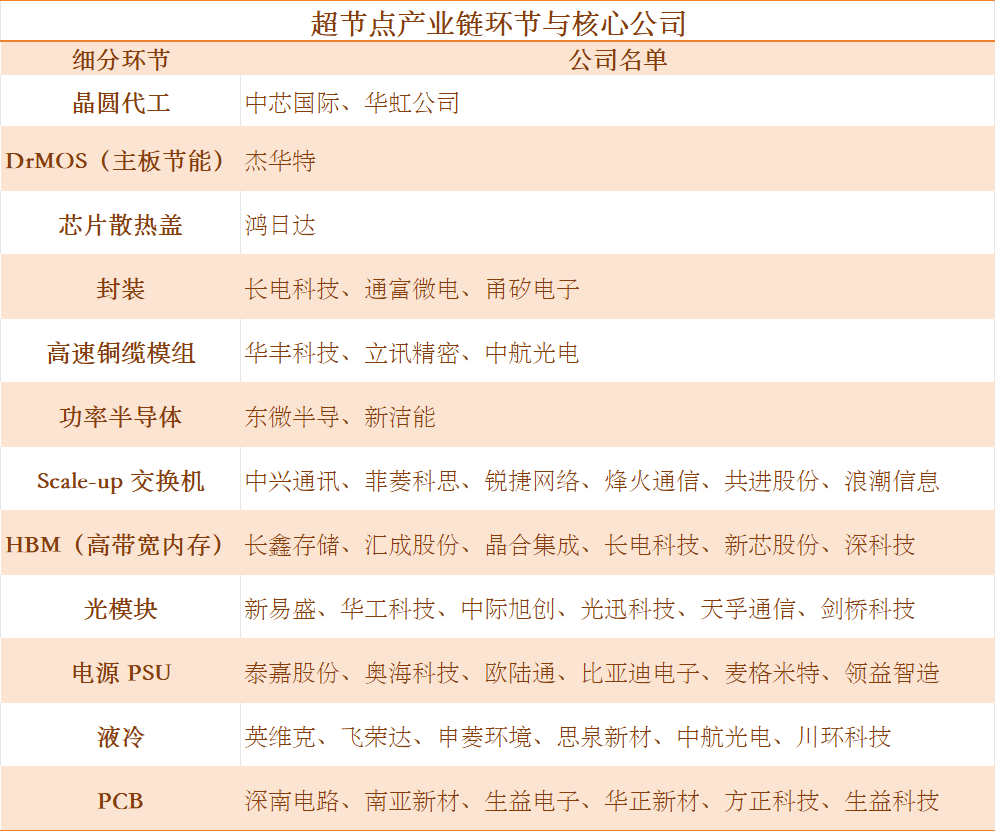
表2:核心假设敏感性分析:
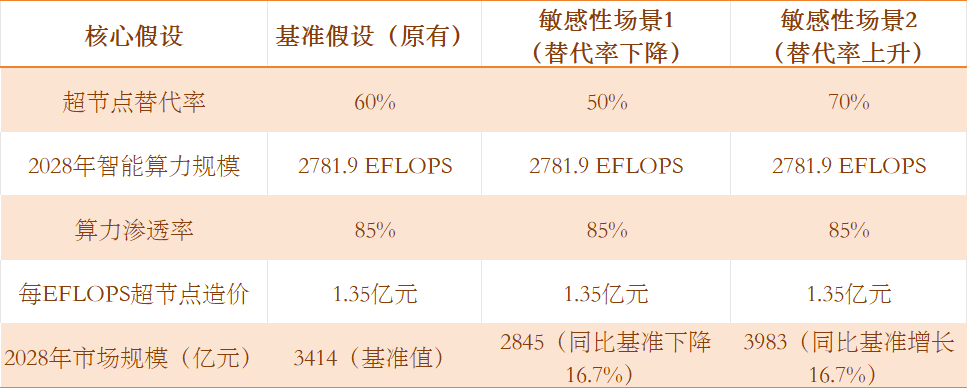
注:测算公式=智能算力规模×算力渗透率×超节点替代率×每EFLOPS超节点造价,替代率是影响市场规模的核心变量,替代率每变动10个百分点,市场规模对应变动约569亿元。
表3:国产超节点核心环节景气度与跟踪指标

风险提示:本文为产业深度研究,不构成任何投资建议。行业技术迭代、原材料价格波动、市场需求变化、政策调整等因素,均可能影响产业发展进程,需理性看待产业长期逻辑与短期波动。
注:本文相关梳理数据仅基于公开统计信息整理、分析,不构成任何投资建议,投资者据此进行投资决策产生的盈亏,均与数据提供方及本报告撰写方无关;数据统计存在时效性,需以最新数据为准。投资有风险,入市需谨慎。
~END~
声明:本文基于公开信息及研报分析,仅供参考,不构成投资建议。市场有风险,投资需谨慎,请独立决策。
来源:金融梦想家
展开阅读全文