抛弃英伟达!华为昇腾领衔国产替代!(附A股核心标的)


热门主题产业链
4月24日,DeepSeek-V4的预览版本正式上线并同步开源。全新的DeepSeek-V4首次抛弃英伟达CUDA生态,全面适配华为昇腾(Ascend)芯片。此次DeepSeek-V4的正式发布,首次实现了国产AI大模型+华为全栈国产算力(昇腾芯片+CANN框架)的完整落地,华为昇腾产业链、国产算力硬件厂商将直接受益。
一、GPU为当前大模型训练及推理主力
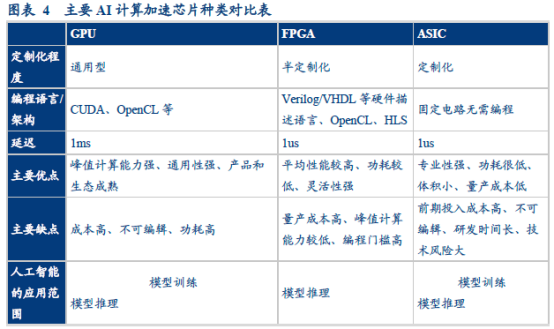
在技术构架角度,AI计算加速芯片可分为GPU、FPGA(Field Programmable Gate Array,可编程逻辑门阵列)、ASIC(Application Specific Integrated Circuit,专用集成电路)和NPU(Neural Processing Unit,神经网络处理器)。
在当前阶段,相较于ASIC和FPGA,GPU在通用计算性能、开发友好性上更具优势,也比处于探索阶段的NPU更为成熟。因此,GPU成为大模型训练和推理领域的主力。未来随着经济社会进步和AI技术的深入发展,更多专业化的AI计算加速芯片也会进入市场。

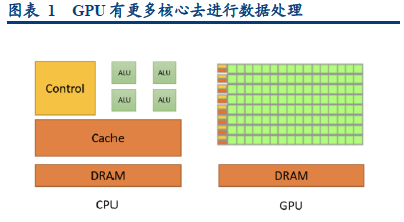
GPU由大量简单核心构成,这些核心并非独立工作,而是被组织成强大的计算阵列,能够同时对海量数据执行相同的简单操作,从而实现减少计算机运行多个程序所需的时间。正是这种独特的并行架构,让GPU成为了驱动现代及未来尖端科技发展的核心引擎。以机器学习 和人工智能领域为例,模型训练均涉及海量矩阵与张量运算,是GPU能够并行处理的理想任务,训练时间因此从数月缩短至数天。
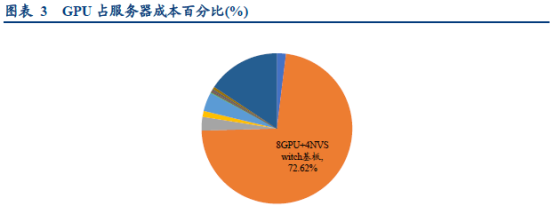
在服务器成本中,GPU占据核心部分。从成本占比看,以英伟达DGXH100为例,8GPU+4NVSwitch基板在服务器总成本中占比达72.62%。在数据呈指数增长、CPU迭代放缓的当下,GPU加速计算优势凸显,是现代高性能计算服务器的核心零部件。
二、英伟达占据全球主导地位
英伟达自1993 年成立起就专注于GPU的设计开发,形成了强大的实力和竞争壁垒。在PC领域,2025 年二季度英伟达独立显卡的市场份额达到94%,断崖式领先于AMD 及其他厂商。随着大模型训练推理需求的兴起,英伟达凭借领先的GPU产品和CUDA生态在AI领域进一步称霸市场。
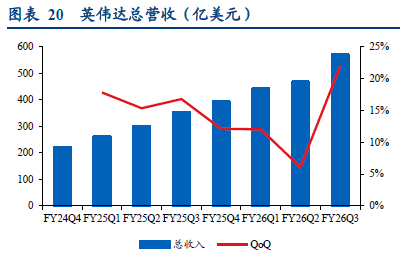
在以GPU芯片为主导的AI数据中心市场,英伟达占据了90%以上的市场份额。在过去四个财季中,英伟达的总收入从Q4FY25的393.3亿美元上涨到Q3FY26的570.1亿美元,Q3同比提升62.5%。其中,数据中心业务收入从355.8亿美元提升至512.2亿美元,Q3同比增长约66.4%,是整体业务增长的核心驱动力。按季度划分,数据中心业务在总收入中的占比分别约为90.5%、88.8%、87.9%、89.8%,显现了市场对于数据中心GPU产品有着强盛需求。
CUDA(Compute Unified Device Architecture)是一套英伟达提供给开发人员的编程工具。它连接主机端和设备端,使得工程师能够直接调用GPU,用其并行结构高效运行计算任务,而无需直接编写底层硬件控制代码。通过CUDA,开发者可以使用C++等高级编程语言来编写复杂的并行算法,充分利用GPU的计算能力来加速实现大模型训练和推理。此外,CUDA还提供了丰富的库和工具集,帮助开发者即使不深入底层硬件也能进一步优化程序性能,从而高度简化开发流程、提高开发效率。从2007年发布以来,CUDA都只能在英伟达平台上使用。

三、国内芯片厂商加速追赶
美国不断升级对华限制导致英伟达高端GPU在中国市场供应几乎被完全切断。在市场空缺和国家战略的双重刺激下,国产芯片企业迎来历史性发展机遇。当前,华为昇腾、寒武纪、海光信息、摩尔线程、沐曦股份等国内厂商推出多款AI智算芯片产品,并逐步追赶国际领先标准。
1)华为昇腾:自研达芬奇构架
华为持续研发昇腾系列商用GPU产品,力争自主可控。华为全资控股的子公司海思科技专门从事半导体及器件设计,2018年华为发布昇腾310(12nm,终端低功耗,最大功耗8W)和昇腾910(7nm,云端高算力,可组成Ascend集群)两款AI芯片,均基于达芬奇架构。在华为中国合作伙伴大会2026上,华为正式发布搭载全新昇腾950PR处理器的AI训练推理加速卡Atlas 350。

2)寒武纪:聚焦人工智能
寒武纪专注于人工智能芯片及基础系统软件的研发设计,近年云端产品线(包括智能芯片、加速卡及训练整机)持续深化与互联网及大模型头部企业的技术合作,产品在自然语言处理场景实现批量出货。思元590基于7nm工艺打造,支持云端和端侧应用,具备314 TFLOPS(FP16)的峰值算力、80GB显存和高达2TB/s的带宽。2024年11月推出的MLU370-X4,FP16 算力为96TFLOPS,配备24GBLPDDR5内存,内存带宽307.2GB/s,最大设计功耗150W,主打高性价比AI加速方案。

3)海光信息:CPU、DCU双线发展
海光信息产品包括海光通用处理器(CPU)和海光协处理器(DCU,GPGPU的一种)。DCU采用通用并行计算架构,能够较好地适配、适应国际主流商业计算软件和人工智能软件。核心产品包括深算一号、深算二号和深算三号,目前深算三号产品进展顺利。

4)摩尔线程:拥有完整GPU产品矩阵
摩尔线程是拥有完整GPU产品矩阵和解决方案的供应商,以自主研发的全功能GPU为核心,自建MUSA架构,致力于向全球提供加速计算的基础设施和一站式解决方案。公司已成功推出四代GPU架构,并形成了以大模型智算加速卡MTT S4000、大模型训推一体机MCCX D800 X1、专业视觉加速卡MTT X300等产品为代表的多元计算加速产品矩阵,产品线涵盖政务与企业级智能计算、数据中心及消费级终端市场。

5)沐曦股份:打造全栈GPU芯片产品
沐曦股份致力于自主研发全栈高性能GPU芯片及计算平台,公司产品采用自主研发的GPU IP和指令集、统一的GPU计算和渲染架构,形成了由用于AI智算的曦思N系列,用于推训一体和通用计算的曦云C系列,以及用于图形渲染的曦彩G系列构成的GPU产品体系和自主开放的软件生态,以满足“高能效”和“高通用性”的算力需求。公司产品涵盖了计算(包括训练、推理、通用计算)和渲染的全场景,并已实现多款高性能GPU产品的量产销售。

四、核心标的
寒武纪:提供云边端一体、软硬件协同的系列化AI芯片及基础系统软件,并已规模应用于大模型算法公司、服务器厂商、云计算、金融、电信等多个行业;已完成DeepSeek-V4-Flash及V4-Pro的Day 0适配。
海光信息:在AI算力领域,海光已打造出全栈软硬件协同体系,并与DeepSeek、Qwen3、ChatGPT、混元、智谱等365款主流大模型完成全面适配与联合精调,覆盖全球99%非闭源大模型。
摩尔线程:基于自研MUSA架构已迭代四代GPU,产品覆盖AI智算、图形渲染等全场景,技术自主可控。
沐曦股份:国内少数实现千卡集群大规模商业化应用的GPU供应商,GPU累计销量已超25000颗。
深圳华强:国内电子元器件授权分销龙头,是华为昇腾APN“金牌部件伙伴”,已完成昇腾边缘AI模组等多款产品开发。
华丰科技:华为高速背板连接器两大国内供应商之一,份额超60%;哈勃科技(华为系)持有公司2.95%。
皖通科技:全资子公司华东电子与华为联合开发“华东智能岸边理货系统-华为版”,该项目基于昇思Mindspore Al框架、异构计算架构CANN。
泰嘉股份:昇腾服务器电源的核心代工方,在昇腾910C/950系列服务器中,份额预计将从20%的初始水平快速飙升至2026年的50%以上。
—End—
(特别说明:文章中的数据和资料来自于公司财报、券商研报、行业报告、企业官网、百度百科等公开资料,本报告力求内容、观点客观公正,但不保证其准确性、完整性、及时性等。文章中的信息或观点不构成任何投资建议,投资人须对任何自主决定的投资行为负责,本人不对因使用本文内容所引发的直接或间接损失负任何责任。)
来源:策金说
展开阅读全文