爆发前夜!AI交换网络再造一个千亿市场,核心龙头全梳理!(附股)


大V说
全球AI竞赛正进入白热化阶段。当各大科技巨头纷纷推出十万卡、百万卡集群计划时,一个根本性问题浮出水面:如何让海量GPU高效协作?答案就在Scale Up(纵向扩展)网络中。
想象一下,数千张GPU芯片犹如一支军队。传统的Scale Out(横向扩展)架构是建立多条公路让军队分队行进,而Scale Up(纵向扩展)则是搭建高速铁路网,让军队在专属通道上疾驰。这个技术突破带来的优势令人震惊:
- 英伟达GB200超节点:推理效率达H100单卡的30倍
- 华为昇腾384:单卡推理吞吐2300 Tokens/s,超越英伟达H100
- ETH-X方案:训练时间减少30%,推理性能提升40%
这种革命性的“超节点”架构,正在重构整个AI算力基础设施的生态格局。
随着大模型参数规模突破万亿级,GPU集群从万卡向十万卡演进,网络性能正成为制约算力效率的关键瓶颈。传统Scale Out(横向扩展)网络架构在应对AI训练的海量参数同步时,暴露出带宽不足、延迟过高的致命缺陷。
超节点技术通过高速互联技术整合多块算力芯片形成规模化计算单元,成为解决AI大模型算力协同的最优解。目前全球两大标杆方案:
- 英伟达GB200 NVL72:2024年推出,内含18个Compute Tray(72个GPU)和9个Switch Tray(18个NVSwitch芯片),单卡算力是H100的2.5倍,训练效率是H100的4倍。
- 华为昇腾384:2025年4月发布,通过总线技术实现384个NPU之间的大带宽低时延互联,解决集群内通信瓶颈。
超节点方案的核心优势在于大幅缩短训练周期和提升推理性价比。在训练方面,由于Scale Up(纵向扩展)网络的通信时间远低于Scale Out(横向扩展)网络,模型训练时间显著降低;在推理方面,超节点能更大限度提升GPU算力利用率,从而提升Tokens输出效率。
全球巨头围绕AI交换网络已形成两大技术阵营:
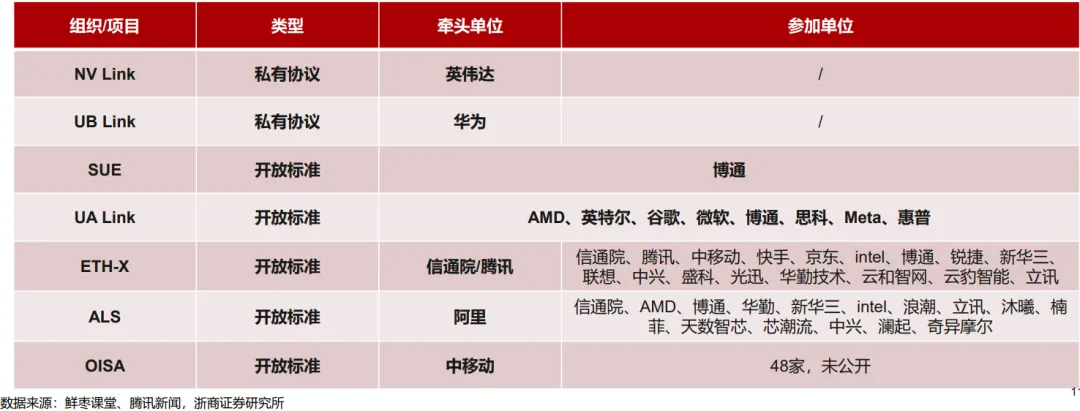

私有协议阵营
- 英伟达NVLink:第五代方案实现1800GB/s 互联带宽,构建GB200 NVL72“算力航母”。NVLink接口让GPU以全带宽速度存取CPU内存,解决了CPU和GPU之间的互联带宽问题。
- 华为UB:在美国制裁背景下打造的自研方案,实现384卡全互联节点,突破技术封锁。
开放标准阵营
- UALink联盟:2024年5月,谷歌、META、微软、AMD、英特尔等八家科技巨头成立联盟,旨在制定AI数据中心加速器互联的开放标准,直接对标英伟达NVLink。
- 腾讯ETH-X:基于以太网升级,首台原型机已点亮
- 阿里ALS:携手AMD打造开放方案,发展国内产业生态
- 博通SUE规范:基于以太网架构,2024年7月推出Tomahawk Arch交换芯片
技术路线之争的核心在于生态控制权。短期内,NVLink凭借成熟度与性能优势仍是主流,但长期将逐步融入以太网生态。650 Group预测,以太网协议在整个AI/ML数据中心交换机市场中的收入份额将持续提升。
落到投资上,技术的变革,带来哪些增量机会?
传统Scale Out(横向扩展)架构中,127张GPU需要48台交换机,GPU:交换机比例仅为2.67:1。而在超节点架构下,72张GPU需要18张NVSwitch芯片,配比跃升至4:1,整体交换网络价值量暴增150%。
据浙商通信分析,2027-2028年国内超节点渗透率就能达到45%、72%,基本同海外只相差一年。华为昇腾384超节点单卡推理吞吐量达2300Tokens/s,计算效率已超过英伟达H100/H800。
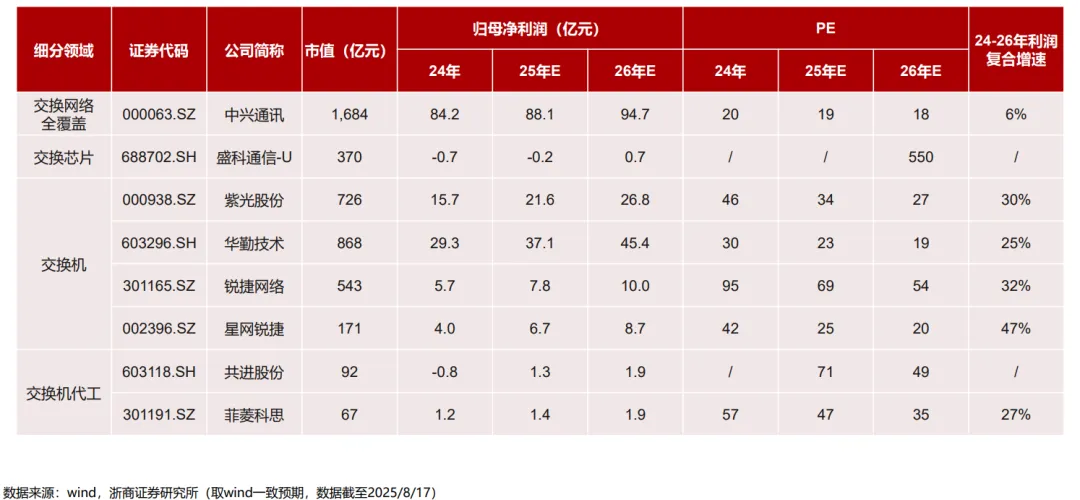
一是交换芯片:国产替代关键突破点
2023年国产化率仅1.6%,博通(61.7%)+美满(20%)垄断市场。核心标的:
盛科通信:国内稀缺的交换芯片制造商,25.6T产品已小批量交付,最大端口速率800G、交换容量12.8T/25.6T的产品已完成向客户送样。
中兴通讯:自研7.2T芯片打造400GE/800GE交换机,在机内互联交换芯片+交换机+训推网络平台方面实现全覆盖。
二是交换机厂商:头部效应显著
华为(35.8%)、新华三(32.4%)、锐捷(14.6%)三强主导。核心标的:
中兴通讯:智算超节点方案实现400GB/S-1.6TB/S带宽,2025年预期PE仅19倍。
华勤技术:ETH-X方案支持51.2Tbps交换芯片。
紫光股份:旗下新华三是国内交换机市场龙头,市占率约35.8%,在高速率、光电融合和国产替代三大趋势中具备深度卡位优势。
锐捷网络:TH5冷板交换机份额领先,在互联网细分市场占38%份额。
三是交换机代工:产业扩张直接受益者
菲菱科思:服务国内头部交换机厂商,数据中心交换机收入同比增100%+。
共进股份:800G交换机出货突破,服务器业务取得进展。
当AI大模型进入十万卡时代,算力的竞争已从单卡性能转向集群效率。在这场决定未来的基础设施革命中,AI交换网络正从“幕后技术”走向舞台中央。
当英伟达宣布推出Spectrum-XGS以太网技术,华为推出昇腾384超节点,阿里发布磐久AI Infra 2.0 128超节点,交换网络作为核心增量环节,正在开启一个千亿级新市场。
来源:大阳金融研究所
展开阅读全文