中金 | AI智道:DeepSeek技术破局,成本下探引领应用百花齐放


科技先锋
2025-02-11
摘要
DeepSeek V3通过技术创新与工程优化,实现了领先的性价比。其采用自主研发的MoE架构,总参数量达671B,每个token激活37B参数,多维度对标GPT-4o。技术突破包括稀疏专家模型MoE、多头注意力机制MLA和创新训练目标MTP,显著提升推理效率。此外,FP8混合精度训练策略首次大规模应用,兼顾稳定性和性价比,训练成本仅为557万美元,耗时不到两个月。V3的API定价低至百万输入tokens 0.5元,大幅降低使用成本,我们认为有望推动大模型应用端广泛普及。
DeepSeek R1系列通过强化学习(RL)实现了推理能力边际突破。R1 Zero跳过了传统的大规模监督微调(SFT)环节,直接通过强化学习训练基础模型,达到比肩OpenAI o1的能力,验证了RL在大语言模型中的应用潜力。R1在R1 zero的基础上进一步优化算法,解决了语言一致性等问题。通过底层优化了Nvidia的PTX指令集,R1系列提高了跨平台兼容性,并为国产芯片适配提供了可能。R1的高效推理和低成本使其在产业应用中潜力释放,我们认为有望进一步推动AI应用的普及与规模化。
DeepSeek Janus-Pro模型在图像理解和生成方面表现出色,实现架构统一。Janus-Pro通过两个编码器分别负责图像理解和生成,共享一个Transformer网络,并采用了三阶段训练优化以提高模型对真实场景的适应能力,模型效果优于Dalle 3等海外成果。
我们认为Deepseek将带来三方面产业影响。1)数据从“规模驱动”向“质量优先”转变;2)蒸馏技术带动轻量化模型满足高性能、高效率,使大规模端侧部署更进一步;3)国内外大厂追随,有望迎来技术平权,工程化能力和生态系统建设仍是企业构建竞争壁垒的关键要素。
风险
技术迭代不及预期,下游商业化不及预期。
Text
正文
DeepSeek V3:技术创新+工程优化,实现极致性价比
DeepSeek通过MoE与MLA算法创新,V3性能对标GPT-4o。DeepSeek-V3采用自主研发的MoE架构,总参数量达到671B,其中每个token会激活37B个参数,并在14.8Ttokens上进行预训练,最终实现多维度对标GPT-4o的能力。其技术突破体现在:
1)稀疏专家模型 MoE:延续DeepSeek-V2的路径,拓展至256个路由专家+1个共享专家,每个token激活8个路由专家、最多被发送到4个节点。DeepSeek V3还引入了冗余专家(redundant experts)的部署策略,即复制高负载专家并冗余部署。这主要是为了在推理阶段,实现MoE不同专家之间的负载均衡。DeepSeek-V3在DeepSeek-V2架构的基础上,提出了一种无辅助损失的负载均衡策略,能最大限度减少负载均衡而导致的性能下降,为MoE中的每个专家引入了一个偏置项(bias term),并将其添加到相应的亲和度分数中,以确定top-K路由。
2)多头注意力机制 MLA:围绕推理阶段的显存、带宽和计算效率展开。通过创新底层软件架构,引入数学变换减少kv cache内存占用,缓解transformer推理时的显存和带宽瓶颈。MLA核心思想是借助低秩分解(LoRA)将大投影矩阵分解为wkv_a和wkv_b两个线性层来代替一个大的Key/Value投影矩阵,wkv_a把输入投影到低维空间,wkv_b再投影回原始维度,同时,RoPE通过旋转Query和Key向量为其添加位置信息。而DeepSeek-V3的MLA包含一种优化的注意力计算方式,即将wkv_b的部分计算融入到注意力分数计算中,减少了后续的矩阵乘法操作,进一步提高了效率。
3)创新训练目标:采用MTP(Multi-token prediction)提升模型性能,实现推理加速。MTP的核心思想是让模型在训练时一次性预测多个未来令牌,而非传统的仅预测下一个令牌。这一设计通过扩展模型的预测范围,增强对上下文的理解能力,并优化训练信号的密度。
图表1:V3采用MTP一次预测多个令牌,计算交叉熵损失,由主模型进行快速验证,将推理速度提升1.8倍
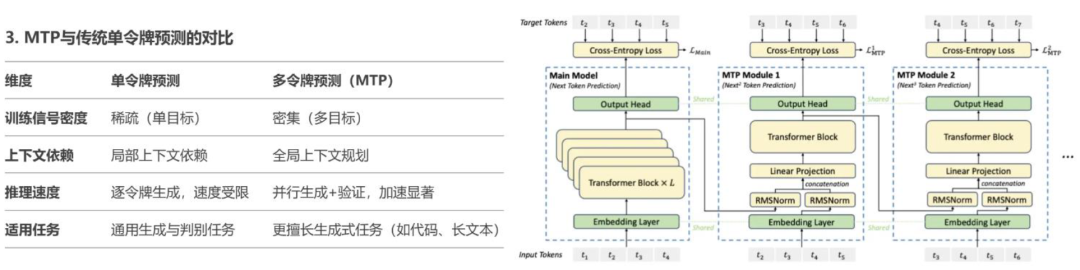

资料来源:DeepSeek-V3 Technical Report https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf,中金公司研究部
创新性大范围落地FP8+混合精度策略,兼顾模型稳定性和性价比。预训练方面,DeepSeek V3采用FP8训练。计算精度从过去主流的FP16降到FP8,保留了混合精度策略,在重要算子模块还保留了FP16/32来保证准确度和收敛性;对于FP8的采用和大量工程化创新,能够兼顾模型稳定性和降低算力成本。在解决通信瓶颈问题上,DeepSeek V3采用DualPipe高效流水线并行算法(单前向后向块对内,重叠计算和通信),只要保持计算通信比率恒定,可以跨节点使用专家门控,实现接近于0的通信开销。后训练部分,用长思维链模型(R1)蒸馏给V3模型,再进行反哺,保持V3输出风格一致性。
图表2:V3采用FP8混合精度训练框架,首次验证FP8在大模型训练中的可行性

资料来源:DeepSeek-V3 Technical Report https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf,中金公司研究部
“性价比”为应用广泛拓展的核心要素。DeepSeek-V3训练成本仅为557万美元,远低于海外模型。单次训练成本557万美元,耗时低于两个月。2024年中,DeepSeek-V2率先掀起国内的大模型价格竞争,率先将推理成本推动到每百万tokens 1元(下降99%),约等于Llama3 70B的七分之一,GPT-4 Turbo的七十分之一[1],随后阿里、字节开始追随降价。高性能配合极致推理性价比,随着性能更强的DeepSeek-V3更新上线,模型API服务定价也将调整为每百万输入tokens 0.5元(缓存命中)/2元(缓存未命中),每百万输出tokens 8元,程序员月均使用成本可控制在10元左右,大幅降低使用成本。
图表3:DeepSeek-V3训练成本557万美元,耗时<2个月

资料来源:DeepSeek-V3 Technical Report https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf,中金公司研究部
图表4:DeepSeek-V3进入最佳性价比三角,以2%成本对标Claude 3.5 Sonnet性能

资料来源:DeepSeek-V3 Technical Report https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf,中金公司研究部
DeepSeek R1 Zero及R1:强化学习打开推理天花板
技术原理:R1 Zero强化学习主导,R1进行SFT与RL融合优化
DeepSeek R1 Zero和R1出圈,R1 Zero具备对标AlphaZero的重要意义。DeepSeek APP于2025年1月11日发布,截至1月31日DAU达2,215万,达ChatGPT DAU的41.6%,超过豆包DAU 1,695万。截至2025年1月,ChatGPT、DeepSeek、豆包排名全球AI产品日活总榜TOP3,DeepSeek霸榜苹果应用商店157个国家地区的第一名(含美国)。DeepSeek MAU达到3,370万,1月末中国MAU占比30%,印度等多国家实现快速渗透[2]。我们认为,技术视角具备重要意义的是R1 Zero对于强化学习(RL)在训练侧的大范围采用,即无需人类监督的SFT,借助RL打开推理能力天花板,与AlphaZero在围棋领域仅凭自对弈强化学习取得的成果相呼应。
图表5:DeepSeek上线21天,DAU达2,215万,排名全球AI产品榜第二名,霸榜157国家和地区苹果应用商店

注:右图单位为百分比(%),为截至2025年1月31日DeepSeek APP MAU按国家占比 资料来源:AI产品榜 aicpb.com,中金公司研究部
技术复盘:回顾早期强化学习到ChatGPT到o1的发展历程,2017年5月,AlphaGo创新性地采用两阶段训练范式,即先基于人类棋谱预训练神经网络,继而通过自我对弈强化学习实现能力跃升,最终以3:0战胜围棋世界冠军柯洁。随后DeepMind推出的AlphaZero实现范式突破,完全依赖自我对弈强化学习即超越前代系统,标志着强化学习技术首次实现突破性进展。至2022年末,ChatGPT通过基于人类反馈的强化学习(RLHF)机制显著提升对话交互能力。2024年OpenAI推出的o1模型开创性引入“AI自主评分”训练范式,弱化人类监督,运用强化学习优化思维链生成,实现类人类慢思考机制,大幅降低对人类反馈的依赖。2025年DeepSeek发布的推理模型R1-Zero,通过完全消除监督式微调过程(SFT)、仅凭强化学习即达到与o1相当的智能水平,向AlphaZero技术路线致敬,更推动强化学习技术迎来第二次重大突破。
图表6:R1-Zero相比o1的突破,可以类比于AlphaZero相较AlphaGo的强化学习突破

资料来源:豆包,公司官网,中金公司研究部
传统大模型训练经历SFT-RLHF环节,R1 Zero绕过SFT环节,剔除人类监督,进行算法颠覆式创新。在大语言模型的训练中,SFT通常被认为是必要环节,先用大量人工标注的数据来让模型初步掌握某种能力,然后再利用人类反馈的强化学习(RLHF)来进一步优化模型的性能。R1-Zero选择将 RL直接应用于基础模型(DeepSeek-V3-Base),而没有经过任何形式的SFT预训练,节约标注成本,不被预先设定的模式所束缚,推理能力突破,具备强大泛化能力和适应性。R1-Zero证实了纯强化学习的有效性,彰显RL潜力。在AIME 2024上,R1-Zero的pass@1指标从15.6%提升至71.0%,经过投票策略(majority voting)后更是提升到了86.7%,与 OpenAI-o1-0912 相当。
图表7:采用群组相对策略优化GRPO算法,R1在数学、代码等任务上比肩 OpenAI o1

资料来源:DeepSeek R1 Technical Report https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf,DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models https://arxiv.org/pdf/2402.03300,中金公司研究部
R1-Zero强推理能力下仍具备语言不一致等问题,R1则以多阶段训练、Cold start的方式解决落地短板。R1则通过“SFT—RL—SFT—RL”过程进一步优化算法,提升产品使用体验。1)SFT 冷启动:基于高质量CoT数据对V3模型进行首次监督微调,给模型打个底,解决语言不一致问题,有助于加速收敛;2)RL 强化学习训练,进一步提升推理能力并引入语言一致性优化;3)SFT 为适应更广泛的非推理任务,构建特定数据集对模型进行二次监督微调,优化其在文本等通用场景下的表现;4)RL 通过混合奖励模型(reward model)进行强化学习,在提升语言流畅度和一致性的同时,平衡推理能力与实用需求,确保模型在实际应用中的稳定性和可用性,平衡推理能力和实用需求。
图表8:基于基座模型V3,R1 Zero仅基于强化学习RL,R1则融合SFT和RL进行优化

资料来源:DeepSeek R1 Technical Report https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf,中金公司研究部
硬件层面优化,本质没有绕开CUDA生态,跨平台兼容性带来国产机遇。DeepSeek底层优化了Nvidia的PTX(Parallel Thread Execution)指令集,本质上没有绕开CUDA生态。相比于直接调用CUDA生态,DeepSeek进行更为精细的硬件层面优化,直接编写PTX代码,得以实现计算效率大幅提升。例如,DeepSeek在H800 GPU上将132个流处理器中的20个专门用于服务器间的通信任务,提升了数据传输效率。“绕开CUDA生态”表述实则意味着跨平台兼容性。DeepSeek直接使用PTX,本质上是对Nvidia CUDA生态的粘性,但其技术可以适配其他GPU平台,如AMD和华为昇腾,展示了其技术的跨平台兼容性。R1的MoE架构和FP8精度未来或推动ASIC芯片适配。
图表9:DeepSeek在硬件层面优化,直接编写PTX代码,本质上没有绕开Nvidia CUDA生态

资料来源:https://developer.download.nvidia.com/compute/cuda/docs/CUDA_Architecture_Overview.pdf,中金公司研究部
产业影响:数据重质少量,R1蒸馏思路带动端云应用规模化落地
性能突出,模型开源,DeepSeek-R1持续破圈。采用预填充与推理分离架构,通过计算与通信过程重叠设计,DeepSeek-R1全面适配国产芯片,推理效率达到英伟达A100的92%[3],超越行业平均65%。FP8混合精度技术使显存占用大幅减少,精度损失控制在0.25%以内[4],兼顾效率与性能。R1系列通过MIT许可证开源模型权重及蒸馏技术,蒸馏小模型性能超越OpenAI o1-mini,吸引全球开发者学习和适配,将进一步推动AI应用增长。
R1训练及推理成本进一步优化,核心要素从性能向成本过渡。DeepSeek-R1在有限算力下做出对标o1能力的模型,R1-zero使用671B总参数,每个token仅激活37B参数,从而实现轻量化调用。DeepSeek-R1 API服务定价为每百万输入tokens 1元(缓存命中)/4元(缓存未命中),每百万输出tokens 16元,调用价格是OpenAI o1的1-5%。
大模型密度定律认为,大模型的效率提升具备规律。我们认为应用层的PMF探索和成本下探趋势下有望百花齐放。面壁智能创始人、清华大学长聘副教授刘知远团队提出大模型的“密度定律”,2023年以来大模型能力密度每3.3个月翻一倍,也就是达到对标最高水平需要的参数量、算力减半,预示着训练成本在现有基础上仍具备持续下探潜力。我们认为,企业级应用、通用及垂类C端应用、手机汽车等端侧部署场景均有望受益于大模型轻量化的效率提升红利。
图表10:面壁智能大模型密度定律:每3.3个月,达到领先模型性能所需的参数量、算力需求减半

资料来源:Xiao,C. et al. Densing Law of LLMs. arXiv preprint arXiv:2412.04315v2,中金公司研究部
基于以上探讨,我们认为DeepSeek-R1产业影响体现在三个方面:
1)国内外大厂追随,有望迎来技术再次平权,工程化能力和生态系统建设仍然是企业构建竞争壁垒的关键要素。在海外,ChatGPT-o3mini、Deep Research以及Google提出的Gemini Flash Thinking等成果亮眼,也具备追随价值。在国内,字节跳动、阿里巴巴等公司在FP8等混合精度量化技术、混合专家模型(MoE)架构以及强化学习训练方法等方面也已具备相应的技术储备,产业链值得密切追踪,行业范围内应用层均有望受益于模型平权、降本。
2)蒸馏成为广泛部署R1能力中小型模型的思路,端侧AI规模化值得关注。知识蒸馏已成为将大型模型的能力迁移至参数规模更小的模型,从而实现广泛部署的有效策略。例如,DeepSeek-R1可以作为教师模型,用于蒸馏Qwen14B等模型。目前,基于蒸馏技术的模型已经覆盖了1B到70B的参数范围[5]。玩具、耳机等端侧硬件有望在小模型赋能下迎来新机遇。
3)数据需求,重质少量:与传统监督学习范式不同,RL训练更侧重于高质量、具备复杂推理链的数据,例如围棋的专家棋谱、数学定理证明过程以及代码规范等,这些数据能够有效引导模型学习策略性决策和逻辑推理能力。而大量日常对话数据对于底层模型优化贡献有限,甚至可能引入噪声,降低训练效率。
DeepSeek Janus-Pro:多模态理解及生成能力超过Dalle 3等模型
Janus-Pro一共包含两个参数模型,分别为1.5B和7B。Janus-Pro 7B在理解和生成两方面都超越了LLaVA、Dalle 3等模型。在多模态理解基准MMBench上,它获得了79.2分的成绩,超越了此前的最佳水平,包括Janus(69.4分)、TokenFlow(68.9分)和MetaMorph(75.2分)。在图像生成评测上,Janus-Pro-7B在GenEval基准测试中达到0.80分,大幅领先于DALL-E 3(0.67分)和Stable Diffusion 3 Medium(0.74分)。
图表11:Janus-Pro 7B在理解和生成两方面都超越了LLaVA、Dalle 3等主流模型

资料来源:DeepSeek Janus-Pro Technical Report https://arxiv.org/pdf/2410.13848 ,中金公司研究部
Janus Pro为模型配置两个编码器共用一个Transformer网络,实现图像生成和理解大一统,符合人脑第一性原理:技术报告中思路与MetaMorph项目(杨立昆和谢赛宁主导)类似,放弃编码器统一,转而采用专门化方案。具体而言,SigLIP编码器负责提取图像的高层语义特征,负责图像理解;VQ编码器负责图像转化为离散的token序列,用于生成创作,两个编码器共用一个Transformer网络。
图表12:Janus-Pro 架构中两个编码器分别负责图像理解、生成,共用一个transformer

资料来源:DeepSeek Janus-Pro Technical Report https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf ,中金公司研究部
多模态统一的概念最早由Google于2023年12月提出,Gemini为代表作,商汤等厂商已采用类似路径。核心在于基于Transformer架构,将文本、图像、音频、视频等多种模态的数据进行统一处理,实现跨模态的理解与生成,实现缩短时延、保留多模态信息完整性的效果。
Janus分为三阶段训练流程,Janus pro在其三阶段都有进一步优化。阶段一:锁定LLM参数,仅通过训练适配器,模型即可掌握复杂的像素依赖关系。Janus pro延长了阶段一的训练时间至25-30%。阶段二:放弃ImageNet训练,仅使用真实的文本到图像数据进行训练,使训练时间减少40%、生成质量提升35%、模型对真实场景的适应性大幅提升。阶段三:在统一预训练的基础上进一步微调模型,这一步Janus的数据混合比例是传统的多模态数据、纯文本数据和文本到图像数据为 7:3:10,Janus Pro创新出更优的配比方案5:1:4,并且创新性引入合成美学数据,和真实数据配比1:1,提升输出图像质量。
投资建议:关注云厂商、AIDC及AI应用投资机遇
主线一:低成本、高性能模型降低用户使用门槛,叠加国产算力适配背景,云CSP、AIDC迎来利好
云CSP方面,我们认为1)云资源消耗量有望提升:Deepseek-R1等模型,因其低成本、高性能的特性,降低了用户接入AI技术的门槛,开发者通过云服务商部署模型、开发应用,有利于应用繁荣、拉动云资源消耗量;2)国产智算资源利用率有望提升:当前华为云、腾讯云、阿里云、百度云、移动云、天翼云、联通云等均已经宣布支持部署DeepSeek模型,华为云指出“凭借其自研的推理加速引擎,双方合作部署的DeepSeek模型能够达到与全球高端GPU部署模型相媲美的效果”[6],我们认为国内云厂商此前布局的国产智算资源利用率或有提升;3)算力需求从训练向推理转化,可能带来云厂商市场格局演进:当下,能够进行高性能训练计算的云厂商占据领先地位,随训练需求继续向推理演进,部分云厂商或可专注于推理服务创造差异化竞争力。国内云厂商或迎来重估机会。
国产算力方面,受益于训练向推理的需求迁移,国产算力适配确定性依然较强,DeepSeek出圈会推动整个国产AI使用度的普及和用量提升,且近期华为昇腾适配积极。
AIDC方面,1)云厂商资本开支提升、第三方数据中心需求提振:过去第三方IDC需求主要来自于传统云计算、短视频等需求,2024年以来国内云厂商资本开支提升,人工智能带来增量需求驱动数据中心订单增长,此外,多家国产AI算力厂商宣布适配DeepSeek,一定程度上缓解了此前因芯片受限而带来的市场对云厂商未来资本开支不及预期的担忧;2)板块估值具有提升空间:板块估值经历近四年调整后,估值处于历史相对低位;3)核心第三方数据中心具估值弹性:服务头部AI厂商、具备快速交付的优质工程能力,并且能够匹配客户训练、推理不同场景需求的数据中心厂商有望获得更大弹性。
主线二:推理成本持续下探,AI应用有望百花齐放
我们认为DeepSeek R1作为高性价比的开源推理模型,能够加速o1性能模型的规模化应用落地,提升AI应用在供给端模型能力的上限。2023-24年基于GPT-4级别的应用没有达到市场的预期,而R1给予工具类应用和Agent应用更多的可能性。
[1]https://mp.weixin.qq.com/s/I14xmlt05u8qDtiTizJgvg
[2]https://mp.weixin.qq.com/s/lWbzaiIm8hRMu9xgy5NFKg
[3]https://mp.weixin.qq.com/s/syjPByXOCRO-jDX7-UO5kw
[4]https://cloud.tencent.com/developer/article/2493520
[5]https://mp.weixin.qq.com/s/TEZxXZ2eHRW_8QBLUX7VzA
[6]https://mp.weixin.qq.com/s/JLRZwgWuYj7NK-W8R2Aw7A
Source
文章来源
本文摘自:2025年2月9日已经发布的《AI智道(2):DeepSeek技术破局,成本下探引领应用百花齐放》
于钟海 分析员 SAC 执证编号:S0080518070011 S FC CE Ref:BOP246
魏鹳霏 分析员 SAC 执证编号:S0080523060019 SFC CE Ref:BSX734
王之昊 分析员 SAC 执证编号:S0080522050001 SFC CE Ref:BSS168
赵丽萍 分析员 SAC 执证编号:S0080516060004 SFC CE Ref:BEH709
车姝韵 分析员 SAC 执证编号:S0080523050005 SFC CE Ref:BTM272
王倩蕾 分析员 SAC 执证编号:S0080524100004
童思艺 分析员 SAC 执证编号:S0080524060015 SFC CE Ref:BVD355
李铭姌 分析员 SAC 执证编号:S0080524070025
---------------------
来源:中金点睛
展开阅读全文
 APP内打开
APP内打开