【一图了解】计算机各行业数据要素相关厂商


科技先锋
线索主要标的
来源:东吴证券
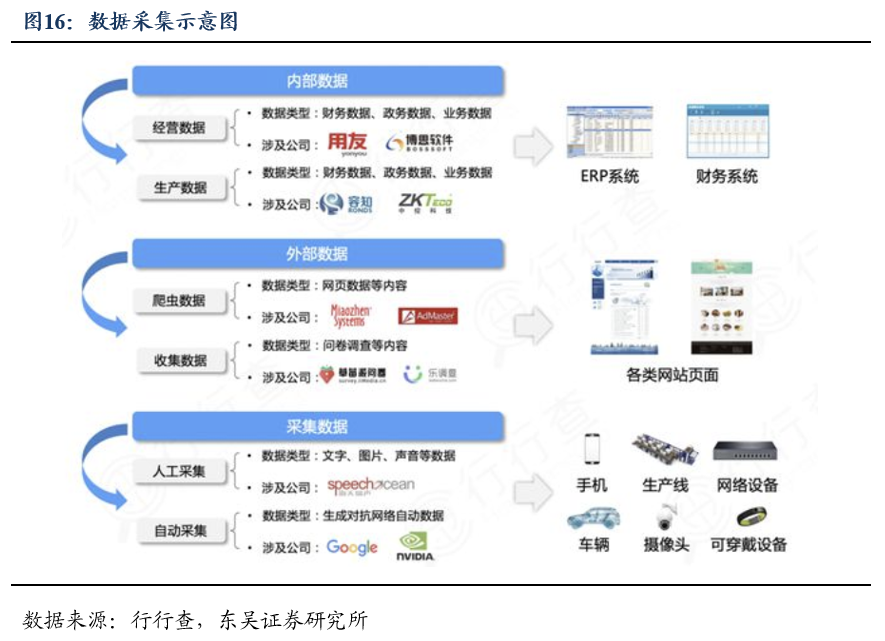
数据资源是AI产业发展的重要驱动力之一。数据集作为数据资源的核心组成部分,是指经过专业化设计、采集、清洗、标注和管理,生产出来的专供人工智能算法模型训练的数据。人工智能应用的数据越多,其获得的结果就越准确。联想集团首席技术官芮勇认为,大模型的特点可以概括为“一大三多”:“‘一大’是指参数规模大,是千亿参数级别的超大型人工智能模型;‘三多’是指利用多来源、多模态、多任务的互联网海量数据进行训练。
大规模语言模型性能强烈依赖于参数规模N,数据集大小D和计算量C。OpenAI 在2020 年曾经提出大模型缩放规律,计算量增加10倍,模型规模要增加5倍,训练数据增加2倍。尽管后来DeepMind重现定义了最优模型训练的参数规模和训练数据量之间的关系,说明数据规模和参数量同等重要,我们仍然可以定性地认为,大模型的性能提升需要依靠持续扩大的数据集实现。互联网提供的海量数据是AI近期能够取得突破性进展的重要基础。
GPT4依靠大量多模态数据训练。GPT4是一个大规模的多模态模型,相比于此前的语言生成模型,数据方面最大的改进之一就是突破纯文字的模态,增加了图像模态的输入,具有强大的图像理解能力,即在预练习阶段输入任意顺序的文本和图画,图画经过 Vision Encoder 向量化、文本经过普通transformer 向量化,两者组成多模的句向量,练习目标仍为 next-word generation。
未来AI模型的竞争力或体现在数据质量和稀缺性:根据Google的研究,数据质量在高风险的人工智能领域具有更高的重要性,但人们往往只关注于模型,而忽略数据质量,在所有AI相关领域几乎都是如此。我们认为GPT-4更多依赖模型效率和数据质量的提升来实现改进,未来在细分垂直行业的优化也将基于行业特定数据展开。
高质量、稀缺的数据放开对AI发展至关重要。发展国内自己的大模型需要国内的高质量、稀缺数据。然而,根据发改委高技术司,我国政府数据资源占全国数据资源的比重超过3/4,开放的规模却不足美国的10%,个人和企业可以利用的规模更是不及美国的7%,但这类数据的开放共享程度不高,全国开放数据集规模仅约为美国的11%,数据有待进一步开放汇集,为开发更符合国内需求的大模型提供基础。发展数据要素市场,促进相关公共、企业、个人数据的进一步放开,将为国内AI发展提供重要支撑。
我们认为可以主要关注两个方面:能够采集、处理细分行业稀缺数据的厂商:久远银海、容知日新、国能日新、千方科技、中控技术、用友网络等,以及具有专业数据处理服务能力的通用第三方厂商:海天瑞声等。



展开阅读全文