chiplet到底是个啥?


大V说
这几天因为M国芯片法案+西婆娘搞事+DJJ反贪腐+瓷砖厂N+2出来+HW依靠3D堆叠封装突破7nm,突然又掀起了市场爆炒3D堆叠+chiplet概念,一波炒半导体新技术的大风口徐徐来袭。
这次和过去不同的是,“国产替代”这个已经听腻了,这次会所里来了一个新的姑娘,她名叫“chiplet”。没听说过吧,也看不懂吧,看不懂就对了。反正是个新的妹子,先上了再说。于是通富微电,大港股份,芯原股份等几个最搭边的被爆炒。
最经典的就是,有几个已经干进这几个票的大佬,事后问我chiplet到底是个啥?
WTF???你们都TM的干进去,还在互相打听?
玩笑归玩笑,洒家观察发现这波的风口的逻辑是3D堆叠封装+chiplet。从实际上来讲,3D封装堆叠属于Fab厂与封装厂争夺的阵地,chiplet属于从系统角度定义新的芯片产业链生态,但是他们有个共同的概念点叫——后摩尔时代。
引爆点是,不知道那条道上的人写了一篇小作文,大致意思是HW用两个14nm芯片通过3D堆叠方式能得到一个7nm,有了7nm不就突破了美国的封锁了吗?禁EUV光刻机也不是瞎折腾了吗?没有EUV光刻机,我们照样搞出7nm 芯片我们很厉害对吧,又赢麻了系列。
紧接着从堆叠芯片又引出一个chiplet的概念,意思是芯片以后都可以通过搭积木的方式制造出来,这不中国就进入后摩尔时代了么。
于是市场最热的三个票,第一封装里的最小市值的公司大港股份,典型的困境反转,这公司外面收购了一堆资产,说是能做3D封装,具体能不能做,做到什么水平,我不知道,但是大佬说你有就是有。
通富微电也是同理,有人说通富微电是三大封装厂里唯一能做的3D封装的,最早实现技术落地的,确实我认识几个干封装的技术大牛都在通富里,做出来我是信的。
第三是chiplet最正宗的公司,芯原股份。道理很简单,IP在手天下不愁,chiplet时代赋予芯原更大的舞台,毕竟要玩chiplet的本质就是不同的IP芯片化后然后搞堆叠方案,当然利好IP公司。
至于那篇游资小作文说华峰测控怎么怎么好,什么设备能测这个能测那个,chiplet时代华峰测控是天下正宗,没长川什么事,我不敢确定华峰的价值,但是我总觉得哪里不对劲。人人都知道华峰主要产品线在模拟和MCU这种芯片测试设备上,但是chiplet目前解决的是高算力芯片的进化,属于数字芯片,因此友情提醒:讲故事,拉高出货,这种故事见太多次了,不得不防。
不要以为把两个裸芯粒(Die),搭线跟连连看似的,弄到一起就叫3D堆叠技术?就是chiplet了啊,新时代马上就来了啊,这套技术比你想的难多了。


你认为的3D堆叠技术
真正的3D堆叠技术
从字面上看chiplet理解为小芯粒技术,这个概念是芯原股份戴老板妹夫周秀文在2015年提出来的,叫Mochi。
当年周秀文提出一个概念:未来芯片设计也许就和乐高积木一样,通过不同的芯片重新组合搞出一个新的芯片。

具体操作方案是,有一个高速SerDes快速接口,把现在已经有的包含部分功能的裸晶粒,通过先进封装技术链接到一起,非常有创意的想法。
当然了,当年周秀文没有成功是因为迈威尔自己没能统一这个高速信号接口,信号接口都不一样,连个毛线啊。
经过这些年的发展又提出了chiplet这个概念。到现在,业界对chiplet的理解是:异构架小芯粒系统级集成。请注意,它包含了异构架,小芯粒,系统级集成三个概念。
异构架很好理解,比如GPU,CPU,DRAM都属于不同的芯片,能不能融合到一起提高芯片的算力?如果合到一起就是异构架融合的概念。
小芯粒也很好理解,小芯粒是相对SoC大核而言。
SoC大核就是把所有功能的IP核全放到一个大的SoC里面去,然后用最先进的工艺把这颗芯片造出来,当然了这样的一个颗SoC芯片,肯定是功能最多,性能最强,算力最强。但是问题也来,这个开发成本,效率,和商业风险都非常高,不是大厂玩不起。
小芯粒的概念是把所需的IP单个拆开来,直接流片生产出芯片,然后再通过封装集成到一起。
所以小芯片模块化设计就是在成本,效率,性能,功耗以及商业风险几个方面取平衡点,是一个很接地气的方案。
洒家估计等产业成熟后,chiplet的方案与SoC方案相比,能削掉一半的成本,砍掉1/3的研发时间,是有可能的。
当然chiplet不是SoC的终结者,准确是说是延伸和补充。chiplet的功耗必然比原生大核SoC高一些,这是很难解决的问题。
第三个系统级集成:
集成包含了两个方面,一个软的,一个硬的。
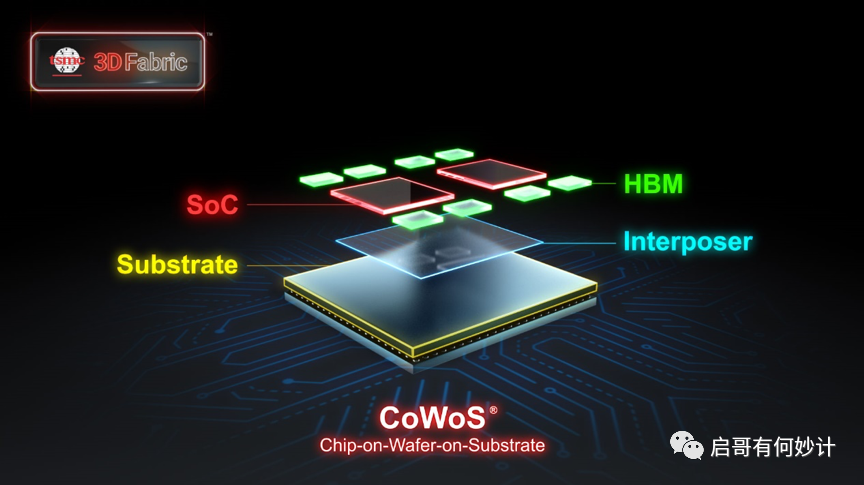
硬件集成这个就是炒3D堆叠封装概念,现在台积电在玩,英特尔在玩,日月光在玩,中国大陆在玩,中国台湾在玩,美国在玩,都在玩,大家都盯着呢。
2014年的苹果iwatch的SIP封装,到后面的AMD的Zen2,等以及此前传的沸沸扬扬的两个14叠一个7nm芯片,都属于早期摸索,从2021年开始应该说业内chiplet概念挺火的,但是二级时隔一年后才能明白过来。
请注意,虽然说3D堆叠封装的概念理解起来很简单,不就是把几个裸芯粒封装到一起么?但是实际要做出来上还是有很大挑战的。
国内产业目前碰到最大的难题就是,做物理仿真计算太困难!因为以前没有做过,没有长期积累数据,更没有好用的软件平台,真的是在瞎子摸象。
但凡干过工业设计的都知道要搞仿真计算,同样芯片也有仿真计算。在如此小的面积里要集成多个裸die,会面临非常复杂的电磁,热,应力,电流等一系列物理问题,随便那个环节处理不好就是就是一大堆芯片失效问题,而且你查都查不出问题出在哪里,因为现在没有啥数据积累,都在摸石头过河。
现在国内外也没有太好的仿真软件来搞定这一切,三大EDA公司也不行,但是你说这东西很难做,难于登天吧,也不至于,主要就是靠长期实验积累,不断优化EDA的仿真计算模型代码即可,因此我觉得这块中国到是挺有机会的。
台积电也是在无数客户陪跑下摸索了整整五年,才总算有点弄明白,国内想要干的好,估计也差不多要好几年后。
软集成,除了软件系统以外,还有最重要的一条就是总线构架问题,不同芯片你要让他们之间通信,比较省钱的方案,就是所有单独功能区的IP核是带有统一的标准的接口,没有的话没法连;要么加一颗总线协议交互芯片,当然这个成本很高。前面当年迈威尔想做当时没有成功的地方就在这里——缺少一个业界统一标准的接口。
不过现在这个业内标准有了,就是UCle联盟,今年3月份这个联盟成立,国内也有不少公司第一时间就加入了联盟,目前我所知道的参与UCle联盟的上市公司就有两个,一个芯原股份,一个澜起科技,芯原的道理很简单不说了,澜起玩的是内存AMB芯片,这东西和构架的总线技术息息相关,当然要加入了。
UCle脱胎于CXL联盟,但是相比CXL联盟只是搞搞接口研究的不同的是,UCle里面多了一大堆硬件制造公司比如台积电,日月光。
然后台积电,日月光都纷纷抛出了自己的工艺平台的全家桶,老实说我直接看啥,以台积电的3D Fabric为例,线宽从40u到150u不等,封装从INFO到SoIC,五花八门,如果前面没有设计好,到封装层面想再弄成“die-to-die”(晶粒直连)那是不可能的。
所以系统级集成的软是统一的总线构架标准,硬是指3D堆叠封装方案。一个赋予神经和血管(互联标准),一个赋予肉体(硬件的die-to-die)。
把上面所有的概念再合到一起就是chiplet的概念。
现阶段chiplet能解决什么问题?又遇到到什么样的困难?
讲这么多我讲一个最实际的能落地的chiplet案例:xPU+DRAM
请记住chiplet目前能之所以叫SoC的延伸和补充,是因为chiplet首先解决的是SoC大核解决不了的难题,即性能/算力增长与付出的成本不成比例。
以GPU为例,不考虑软件的问题,其实再叠晶体管性能增长非常有限,系统瓶颈并不是在算力单元上,而且是在内存上。
讲个通俗易懂的,你找几个肌肉男来拖地,虽然拖地非常快,但是换水捅的跟不上节奏,这地拖干净的时间依然快不起来,解决方案就是第一提高水桶的换水速度,第二是换个更大的水桶减少换水次数。
GPU这样的SoC面积里是寸土寸金的,上大量缓存是严重的浪费晶体管数量的做法,但是不上又不行,所以最简单的方案就是把内存颗粒直接和GPU核心封装到一起,毕竟你通过PCB主板直连,速度只有几百M,但是芯片内部直连可以做到小几百G,速度差1000倍,性能不久嗖嗖嗖的上来了吗?DRAM和GPU的传输距离大幅度降低,Pi是数量级的上升,确实NV也是这么干的。
典型的xPU+DRAM的方案就这么玩,搞一个巨大的前端总线,然后和内存直连,增加带宽,降低损耗,极大的提高系统速度。因此目前阶段,是从应用端出发,以整个系统构架来定义效率最高的chiplet方案。
因此现阶段来看chiplet依然是高高在上的东西,chiplet现阶段只是解决大核SoC解决不了的算力和成本的增长问题,其他领域还没有大规模应用的可能。
我反复提醒各位华峰测控可能是讲故事的原因是,就是目前国内chiplet没有下游需求,没有应用,就算有的也全是HPC(高性能计算)方向的,类似Ai/CPU/GPGPU/DPU这类,显然这不是华峰测试设备所擅长的领域,而且国内这些领域到底谁能跑出来都还不知道。
至于小作文传的把高压,模拟,MEMS,控制,MCU等东西整合到一起,构建芯片的新chiplet时代是有可能的, 但是目前还早,这东西要面临的问题太多了。
来源:锦缎
展开阅读全文